Table of contents
Open Table of contents
Introduction
随着深度学习中的数据规模和网络规模越来越大,训练神经网络会耗费越来越多的时间,势必需要从单 GPU 训练向多 GPU 训练甚至多机训练进行扩展。比如在大规模人脸识别中,训练上千万人脸 ID 需要对最后的全连接层做模型并行,而 GPT-3 为代表的大模型更是有 1750 亿参数,需要在多台机器上做流水并行才能训起来。
近年来除了算力增长非常迅速外,深度学习框架近也在飞速发展,分布式并行的实现变得越来越成熟,不同的细节实现对最后的性能也有着很大的影响,下面简单介绍一下其中的一些并行方式作为扫盲,如有问题,欢迎拍砖。
Data Parallel
第一种并行方式叫做数据并行,也是现在最流行的一种并行方式。当一块 GPU 可以存储下整个模型时,可以采用数据并行的方式获得更准确的梯度,同时还可以加速训练。主要的方式为每个 GPU 复制一份模型,将一个 batch 的样本平均分为多份,分别输入到不同的卡上做并行计算。
因为求导以及加和都是线性的,所以数据并行在数学上是等价的。假设一个 batch 有 n 个样本,一共有 k 个 GPU,第 j 个 GPU 分到 个样本,考虑等分情况,则 ,如果考虑总损失函数 loss 对参数 w 求导,则有
从上面的计算公式中可以看出,所有卡上总 batch 的平均梯度,和单卡上 mini-batch 的平均梯度汇总之后在平均的结果是一样的。
在 PyTorch 中,数据并行主要有两种实现方式:DataParallel 和 DistributedDataParallel。
DataParallel
在 PyTorch 中,DataParallel 的使用非常方便,只需要下面一行代码,就可以将原本单卡的 module 改成多卡的数据并行
model = nn.DataParallel(model, device_ids=[0,1,2,3])DataParallel 的原理可以参考下面的图片
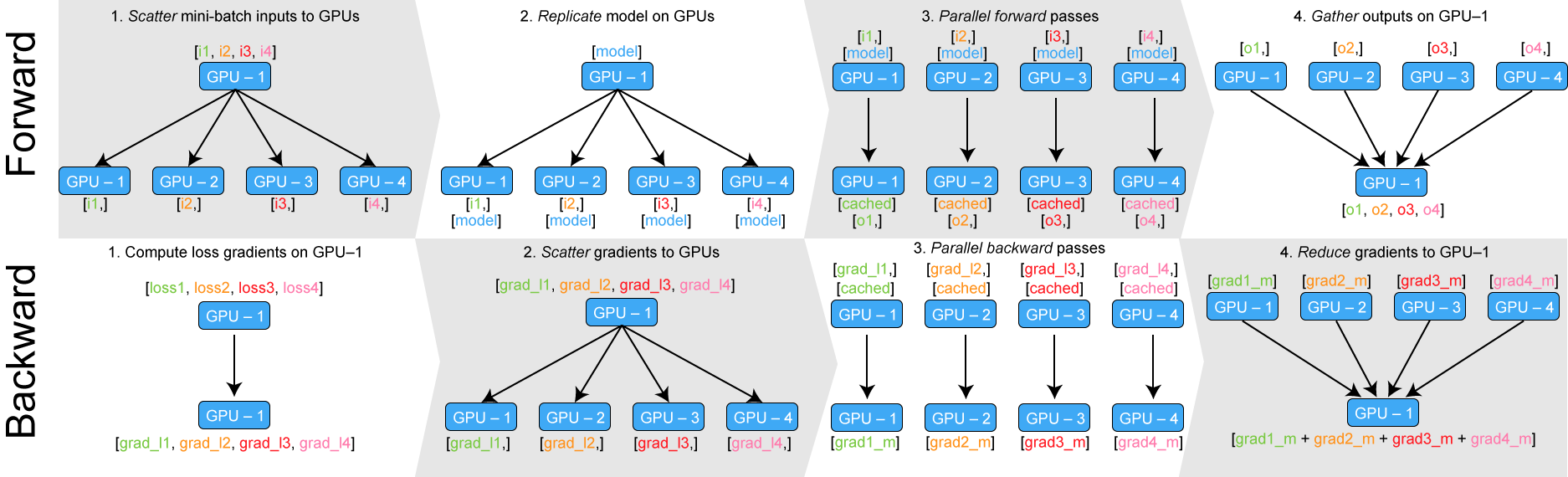 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
在前向的计算过程中,将数据平分到不同的卡上,同时将模型也复制到不同的卡上,然后在每张卡上并行做计算,最后在 device[0] 上获取所有卡上的计算结果。
在反向的计算过程中,在 device[0] 上用 outputs 和 label 计算相应的 loss ,然后计算 outputs 的梯度,接着将梯度发回到每张卡上,然后在每张卡上并行做反向传播得到对应的梯度,最后再一次将不同卡的梯度收集到 device[0] 上,然后在 device[0] 上做梯度下降更新参数。
通过上面的流程,可以发现 device[0] 会比其他 device 使用更多次,而且因为所有的 loss 以及 loss 的梯度都是在 device[0] 上进行的计算的,所以也会出现负载不均衡的问题。
有一种简单的方法可以缓解负载均衡问题,就是将 loss 计算放到网络前向中,这样在前向计算结束之后,device[0] 上获取的就是每张卡上 loss 的计算结果,然后再并行的在每张卡上进行反向传播计算梯度,整体计算流和下面的 Parameter Server 类似
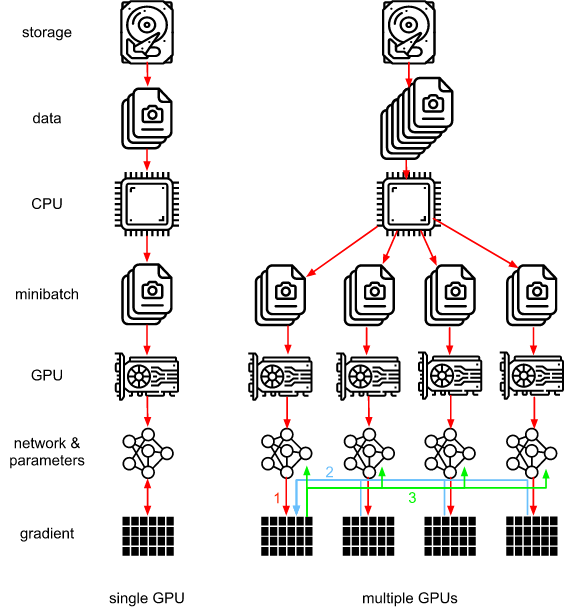 https://d2l.ai/chapter_computational-performance/parameterserver.html
https://d2l.ai/chapter_computational-performance/parameterserver.html
过程一(红色部分): 各卡分别计算损失和梯度;
过程二(蓝色部分): 所有梯度整合到 device[0];
过程三(绿色部分): device[0] 进行参数更新,分发参数到其他卡上;
Parameter Servers 的核心概念在 [Smola & Narayanamurthy, 2010] 中引入,实现非常简洁,不过整体上还是有一些缺点
- device[0] 会被更多的使用,从而导致 bottleneck 出现;
- 负载均衡问题,不同的卡所占的显存不一致;
- 通信开销很大,同步策略非常慢,假设有 k 个 GPU,完成一次通信需要时间 t ,如果使用 PS 算法,总共耗时
- 在 PyTorch 的实现中,使用 Python 单进程,会有 GIL 锁,并不是真正的并发执行
PyTorch 在很早的版本引入了上述实现方式的 DataParallel,不过他们也意识到了这个版本的效率问题,所以后续版本中提出了一个效率更高的数据并行方法 DistributedDataParallel,同时在目前 PyTorch 1.8 版本中官方也更推荐使用 DistributedDataParallel 这种方式。
DistributedDataParallel
DDP 是 DP 的升级版本,调用方式如下
model = nn.DistirbutedDataParallel(model, device_ids=[rank])他们大致原理是类似的,不过有很多细节上的区别,使得 DDP 效率更高,主要的区别如下:
-
多进程. 使用多进程支持真正的高并发,官方推荐做法是每张卡一个进程,从而避免单进程多线程的 GIL 问题,当然也支持多张卡在一个进程上,这样就和 DP 一样使用的多线程;
-
通信效率. DP 的通信成本随 GPU 数量线性增加,而 DDP 使用 Ring AllReduce,保证通讯成本与 GPU 数量无关,能够扩展到大规模分布式训练中;
-
同步参数方式. DP 通过收集梯度到 device[0],在 device[0] 进行梯度更新,然后再将参数分发到其他所有设备上;DDP 则通过保证初始状态相同而且改变量也相同(同步梯度)的方式,保证模型同步和更新;
下面我们重点讲一下 Ring Allreduce,这是效率提升的关键。
Ring Allreduce
Ring Allreduce 原本是 HPC 领域一种比较成熟的通信算法,后被 Baidu SVAIL 引入到深度学习的训练当中,并与 2017 年 2 月公开。
下面两张图直观的看到 allreduce 和 ring allreduce 之间的差别,allreduce 有一个中心参数服务器,而 ring allreduce 则像他的名字一样,构成了一个环。
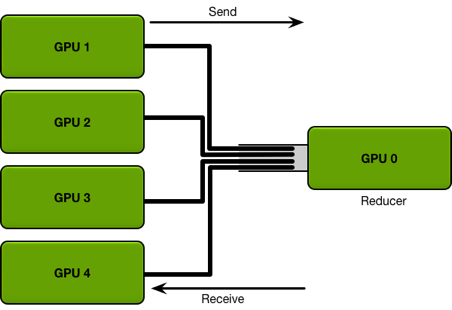
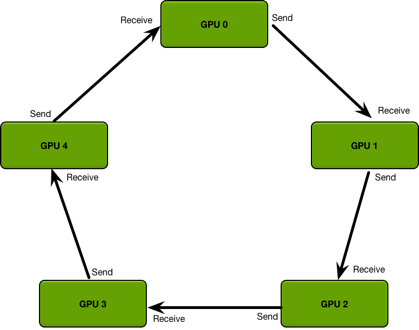
下面我们具体来讲讲 ring allreduce 是如何进行梯度同步,从而保证总体同步和 GPU 数目无关。

上面的动图展示了第一个成环的过程,每个 GPU 都接受来自另外上一个 GPU 的信息,同时发送给下一个 GPU,且每次发送的数据和 GPU 数量 k 成反比,即每张卡不会将这张卡上所有的数据都发给下一张卡,只会发 的数据量。
在上面的例子中,一共有 5 个 GPU 参与通信,所以每次传递 的数据量,第一次传递是从对角线开始,以第一份参数为例,在第一次传递中, GPU-0 将 传递给 GPU-1,完成传递后, GPU-1 的第一份参数就变成了 ,这时 GPU-1 在进行下一次传递,将 传递给 GPU-2,这样 GPU-2 的第一份参数就变成了 ,以此类推,通过 k-1 次传递之后,会获得下图的情况
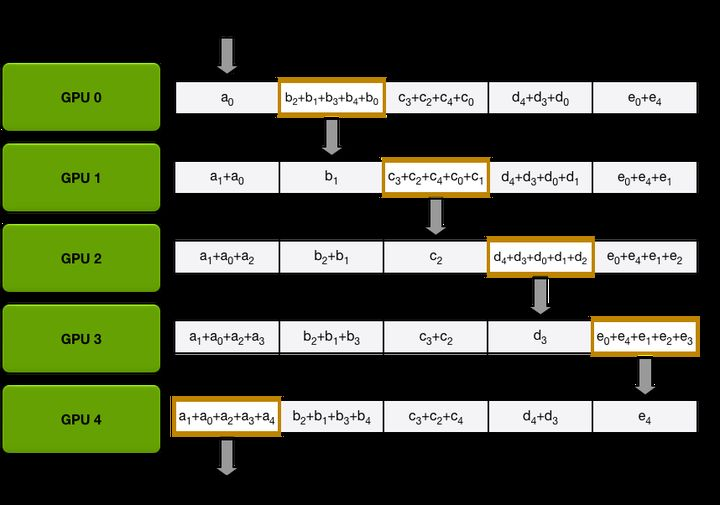
这时可以发现在每张 GPU 上都有一份参数是完整的,比如 GPU-0 上,第二份参数 已经完整地收集到了所有卡上的数据,接着将上图橙色框的数据分别再做 k-1 次传递,最后就可以在每张卡上获得完整的数据信息。
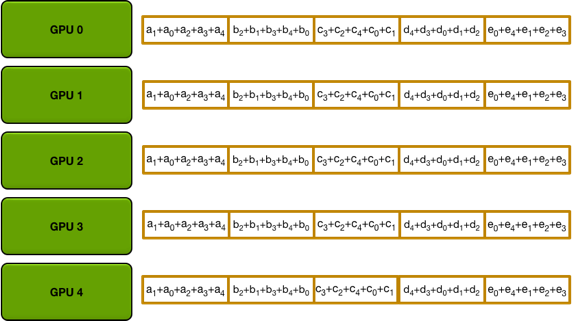
可以分析一下通信开销,假设有 k 个 GPU,传输总量是 p,b 为每次的通信上限,首先将梯度分为 k 份,每张卡每次传输 的通信量,传递 k-1 次就可以分别在每张卡上收集到 完整的数据,之后再传 k-1 次可以使得每张卡上获得完整的数据,所以总的通信开销是
所以整个式子在 k 很大的时候,和 k 是无关的,也证明了 ring allreduce 在通信上是和 GPU 数量无关的。
Model Parallel
上面讲的数据并行需要一张卡能够装下模型,当模型非常大,一张 GPU 无法放下模型的所有 tensor 时,就需要用到 model parallel,也叫做 tensor parallel。随着 GPT-3 等超级大模型的流行,未来模型越来越大也会是一个趋势,所以不要觉得一个模型需要用多张 GPU 来存放是一件离我们很遥远的事情。
说到模型并行,下面有一个简单的例子,这是从 pytorch forum 里面截取的,把模型的第一层 Linear 放到了 device[0] 上,第二层 Linear 放到了 device[1] 上,那么这个能被成为模型并行吗?
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))其实从严格意义上来讲,这个并不能称为模型并行,只是把同一个模型的不同层 split 到不同的 device 上,真正的模型并行还需要是的他们能够同步执行 (concurrently),但是上面的例子中,两个 Linear 并不能同时计算,第二个 Linear 需要获取第一个 Linear 的输出才能进行计算。
那么如何能够写一个简单的模型并行例子呢?在 PyTorch model parallel tutorial 中,给出了一个简单的例子。
得益于 PyTorch 使用的 CUDA operations 是异步的,所以可以用下面的方式来轻松构建一个模型并行的操作,而不需要使用到多线程或是多进程。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)在上面的例子中,首先提前在 device[0] 做一次计算,然后将结果 copy 到 device[1] 上,接着在进行后续的计算。后续是一个 for loop,代码顺序是先执行 device[1] 上运算 A,不过因为 CUDA 的异步特性,这个计算 A 并不会马上执行,随后代码上再执行 device[0] 上的计算 B,这时两个操作 A 和 B 会一起进行计算。等待 B 计算完毕后,会再次实现和之前一样的操作,将 tensor 从 device[0] 上 copy 到 device[1] 上,因为在 cuda 上 device-to-device 的操作会在当前 streams 上进行同步,而上面的实现在 device[0] 和 device[1] 上都使用的是默认的 streams,所以不需要额外进行同步。
其实在上面的实现中,使用了流水并行的技巧,后面我们会更详细的讲解。
Partial-FC
最后我们以人脸识别为模型并行的一个经典例子,介绍其中应用非常广泛的 FC 并行以及他的一种变种 Partial-FC。
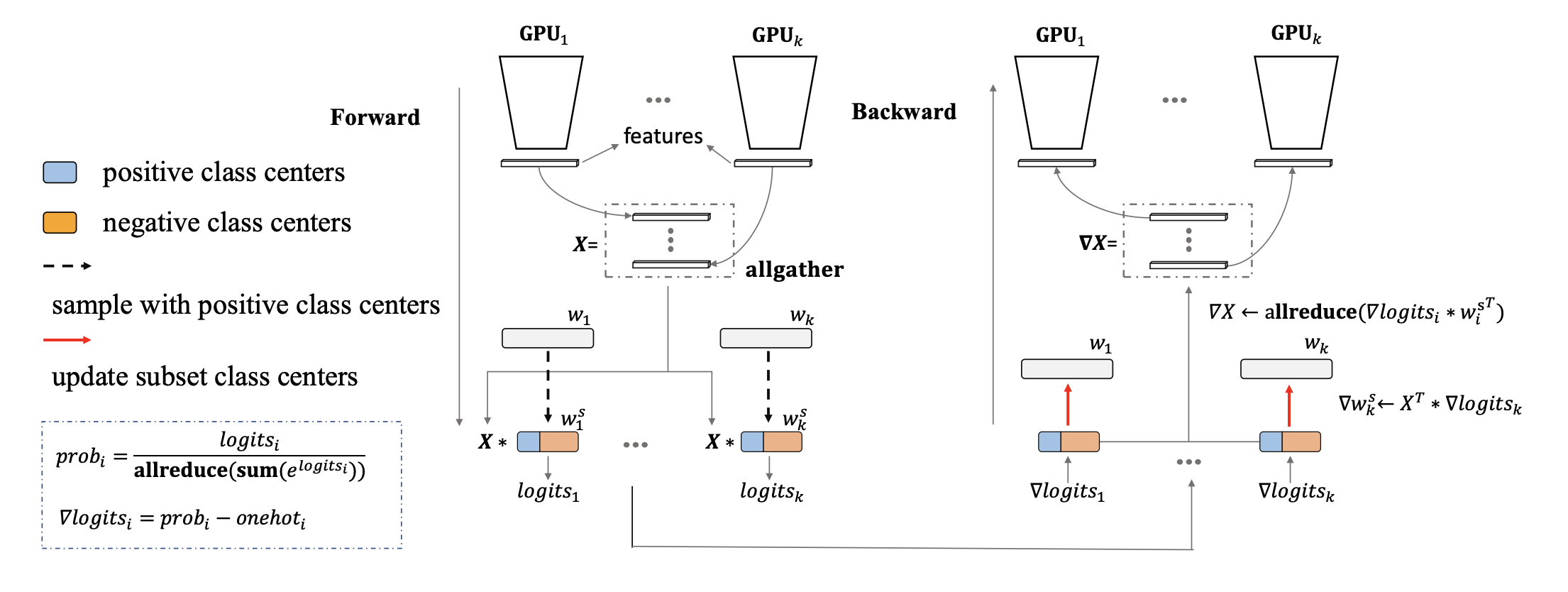 [Partial FC: Training 10 Million Identities on a Single Machine](https://arxiv.org/pdf/2010.05222.pdf)
[Partial FC: Training 10 Million Identities on a Single Machine](https://arxiv.org/pdf/2010.05222.pdf)
上面是人脸识别中模型并行的经典图示,在 Backbone 部分做数据并行,在 FC 部分做模型并行,比如一共有 C 个 ID,k 张 GPU,那么每个 GPU 上会放 类别中心。
整体的计算过程如下:
- 将数据分到不同的卡上,在 backbone 上并行做前向计算得到 features X;
- 每张卡上都同步其他所有卡的 features,然后在每张卡上并行计算对应类别中心的 logits;
- 每张卡上同步其他卡上的 logits 结果,并行计算 loss 以及 logits 对应的梯度;
- 在每张卡上并行计算各自类别中心权重 对应的梯度 和 feature X 对应的梯度 ;
- 同步其他所有卡的 ,获得平均梯度,然后将其 scatter 到各自对应的卡上,并行做自动求导,获得 backbone 的梯度;
以上过程就是人脸识别中标准的 FC 并行框架,不过这种方式的并行会出现一些显存问题,我们可以看看下面的公式
上面分别表示每个 GPU 上权重 w 的显存和计算 logits 的显存,其中 d 表示 feature 维度,C 是类别数目,k 是 GPU 数量,N 是 mini-batch size,4 bytes 表示用 float32 进行计算。
通过上面的计算公式可以看出,如果增加一倍 ID 规模,那么可以通过增加一倍的 GPU 数量 k 来保证每张卡上的显存占用量一致,不过通过观察 logits 的显存占用量就会发现,如果不断地增加 GPU 数量 k,会导致 logits 的显存占用量线性增长,所以随着 ID 规模的增加,不断增加 GPU 数目最终会导致显存爆炸。
Partial-FC 提供了一个非常简单的思路来解决这个问题,既然 logits 显存会随着 GPU 数量一直增加,那么减少 logits 的显存就可以了。接着通过实验发现采样部分负样本和全部负样本最后的收敛效果几乎一致,所以在 Partial-FC 中,每次计算 logits 并不会使用 w 中的全部负样本,只会采样固定比例的负样本,最终可以使得计算的 logits 显存以固定比例降低。
Pipeline Parallelism
最后讲一下流水并行,当模型非常巨大,需要用多张 GPU 进行存储的时候,就需要用到流水并行。流水线并行算是广义模型并行的一种特例,通过多个设备来共同分担显存消耗,同时只在相邻的设备之间进行通讯,因此通信张量较小。
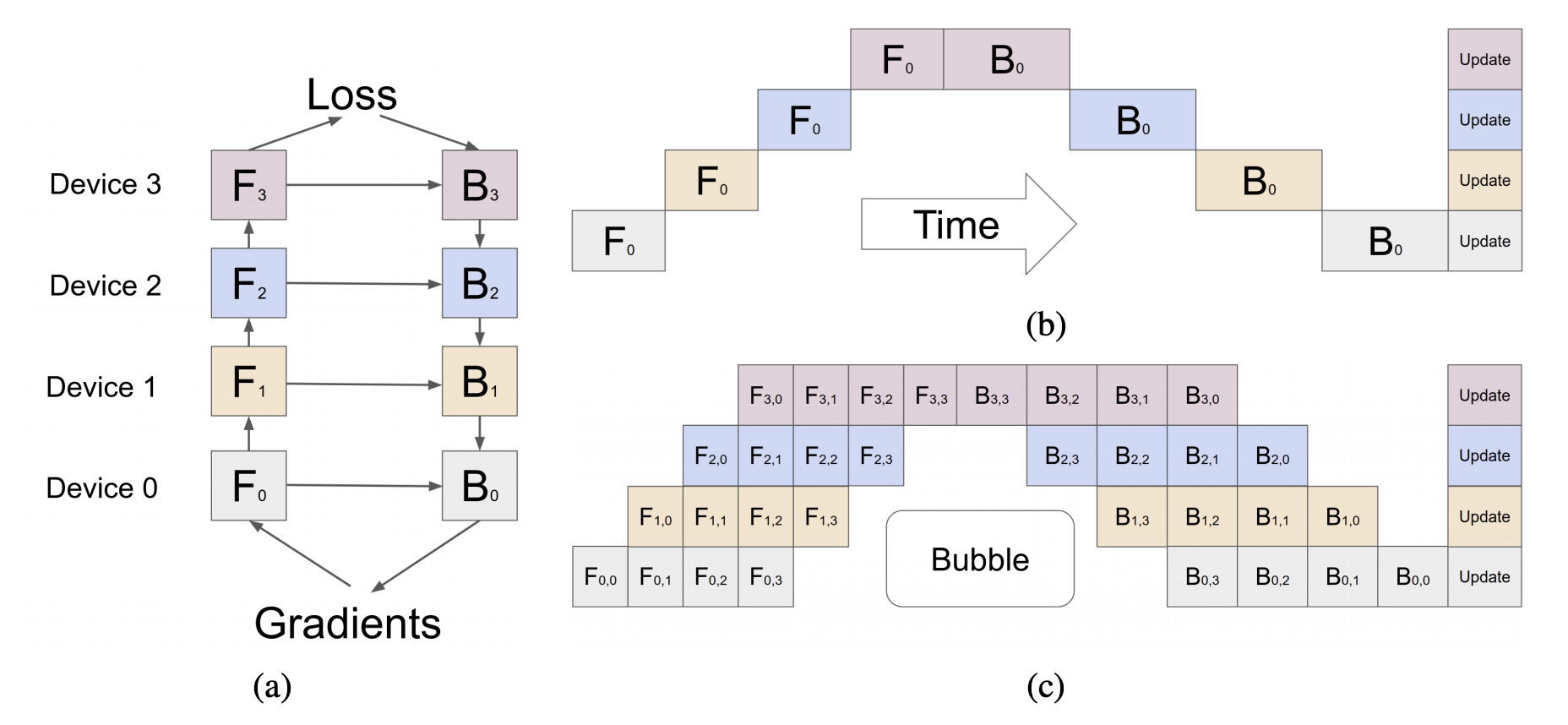
GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
上图中 (a) 展示了流水并行的前向反向计算流,(b) 表示一种 naive pipeline parallelism,同步更新和串行计算,后一个设备依赖上一个设备的结果,所以每次都只有一个设备在计算,其他设备在等待,没有发挥分布式的优势。
(c) 是 GPipe 这篇论文提出了一个解决方案,将一个 mini-batch 切分成多个更小的 micro-batch,实现不同的 GPU 并行同步计算,每个 micro-batch 反向计算获得的梯度进行累加,在最后一个 micro-batch 累加结束之后,再统一更新模型。有兴趣的同学可以直接去看 GPipe 这篇论文。
混合并行
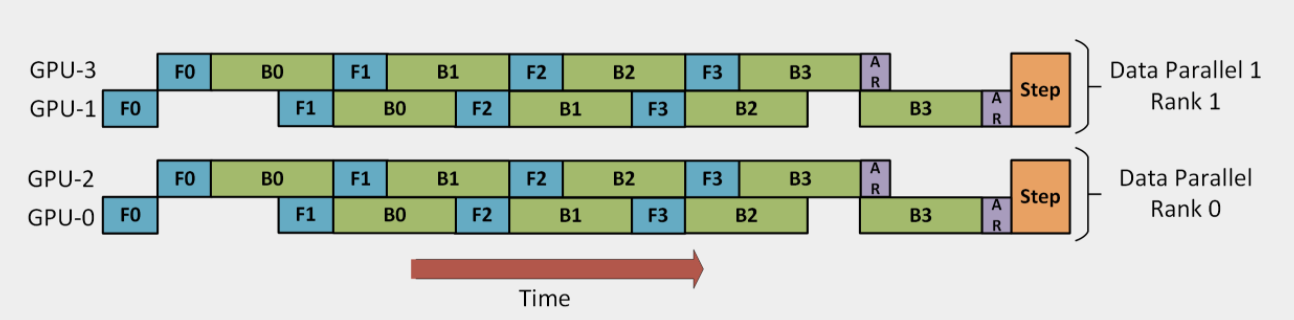
https://www.deepspeed.ai/tutorials/pipeline/
上面讲了多种并行方式一般会混合使用,当多种并行同时使用的时候,也叫做混合并行。上面是从微软发布的 DeepSpeed 的 tutorial 贴出一个例子,主要使用了数据并行 + 流水并行,GPU-0 和 GPU-2 作为 Group-1,GPU-1 和 GPU-3 作为 Group-2,Group-1 和 Group-2 进行数据并行,而在每个 Group 内部进行流水并行,将 Group 内的 batch 数据切分成 4 个 micro-batch。另外 Deep Speed 还提供了一些其他的 features,比如 ZeRO 可以降低内存开销,训练更大的模型,有兴趣的同学可以自行查看。
Further Reading
分布式并行是深度学习中的一个重要的问题,随着数据,算力和模型的规模都越来越大,如何高效、稳定地训练模型也变得越来越重要,上面介绍的并行只是一个入门的内容,有兴趣的同学可以看看这篇 oneflow 的文章 OneFlow —— 让每一位算法工程师都有能力训练 GPT,用 GPT-3 作为例子介绍了分布式训练模型的一些最新的技术。
Reference
- PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析
- https://d2l.ai/chapter_computational-performance/parameterserver.html
- Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- Visual intuition on ring-Allreduce for distributed Deep Learning
- Bringing HPC Techniques to Deep Learning
- 单机多卡的正确打开方式(一):理论基础
- Partial FC: Training 10 Million Identities on a Single Machine
- PyTorch tutorial
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
- Deep Speed
- OneFlow —— 让每一位算法工程师都有能力训练 GPT