LLM 一般分为两个阶段的训练,第一个阶段是 unsupervised pre-train, 不仅需要大量的 data,也需要很多计算资源;第二个阶段是 alignment,不仅包括 instruction tuning,还有 RLHF,这个阶段需要的计算资源和数量都远小于 pre-train,所以可以看到几乎全世界所有的机构都在 alignment 流程上分布式想 idea,也做了很多开源的工作。
最开始大家都只能在一些比较差的开源 base model 上做一些工作,做的效果也都差强人意。 但是随着 LLaMA1 的开源,这个问题就不复存在了,同时由于开源社区可以尽情调用 gpt3.5 和 gpt4 来生成 instruction data,alignment 阶段做的工作也有了非常 promising 的进展。 其中最有代表性的就是 WizardLM 和 Ocra,下面介绍一下这两篇工作以及我对 alignment 上的一些思考。
Table of contents
Open Table of contents
WizardLM
首先介绍 WizardLM2 这篇论文,这篇论文主要 focus 在 instruction data 的自动生成上。 因为学界没有那么多商业上的限制,所以可以通过 gpt3.5/gpt4 来生成 instruction data,这样就不用依赖复杂的人工标注也可以获得大量的 instruction data, 代表性的工作如 self-instruct3, stanford_alpaca 等等。
不过这些工作都存在共同的问题,就是生成的 instruction data 在多样性上存在欠缺。 这里的多样性不只是说 domain 上的多样性,也包含复杂度上的多样性,即简单指令到复杂指令需要均匀分布,如果全部是简单指令,模型无法学会复杂任务; 如果全部是复杂指令,对于模型来说不存在循序渐进的学习过程,会导致模型学不会 CoT 的能力。
所以在复杂度上的 diversity 非常重要,之前 instruction 生成的方法都没有充分考虑这个问题,这导致 instruction 和人类标注相比存在差距,在 LLM alignment 阶段获得效果也就非常一般了。
WizardLM 主要是提出了一种叫 Evol-Instruct 的方法来生成 instruction data,这种方法甚至超过了 ShareGPT4,要知道 ShareGPT 的数据都是用户在使用过程中所创造的,在经过筛选之后,已经算是质量非常高的数据了。
那么 Evol-Instruct 到底是怎么做的呢?主要的步骤有 3 个:
- instruction evolving;
- response generation;
- elimination evolving;
简单来说,从一个初始的 instruction pool dataset 出发,每一轮通过 Instruction Evolver 对每个指令进行进化,然后通过 response generator 生成 response,最后通过 elimination Evolver 对 instruction/response 进行筛选,将成功的结果放回 instruction pool 中。
下面我们来具体讲一下这三个步骤。
Instruction Evolving
在 Instruction Evolving 阶段,主要是通过两种方式来扩展 instruction,分别是 In-Depth 和 In-Breadth.
Prompts of In-Depth Evolving. 这个阶段主要是希望指令更加复杂和困难,通过 5 种类型的 prompts: add constraints, deepening, concretizing, increase reasoning steps 和 complicating input 逐步增加指令的复杂度。这种难度的递进非常重要,可以保证整个数据集中难度分布是均匀的,对模型的泛化能力非常有用。
Prompts of In-Breadth Evolving. 这个阶段主要是希望增加 topic 的覆盖度和数据的多样性,设计 prompt 使得生成的 instruction 更加长尾。
下面是 In-Depth 和 In-Breadth 的一个简单示例。
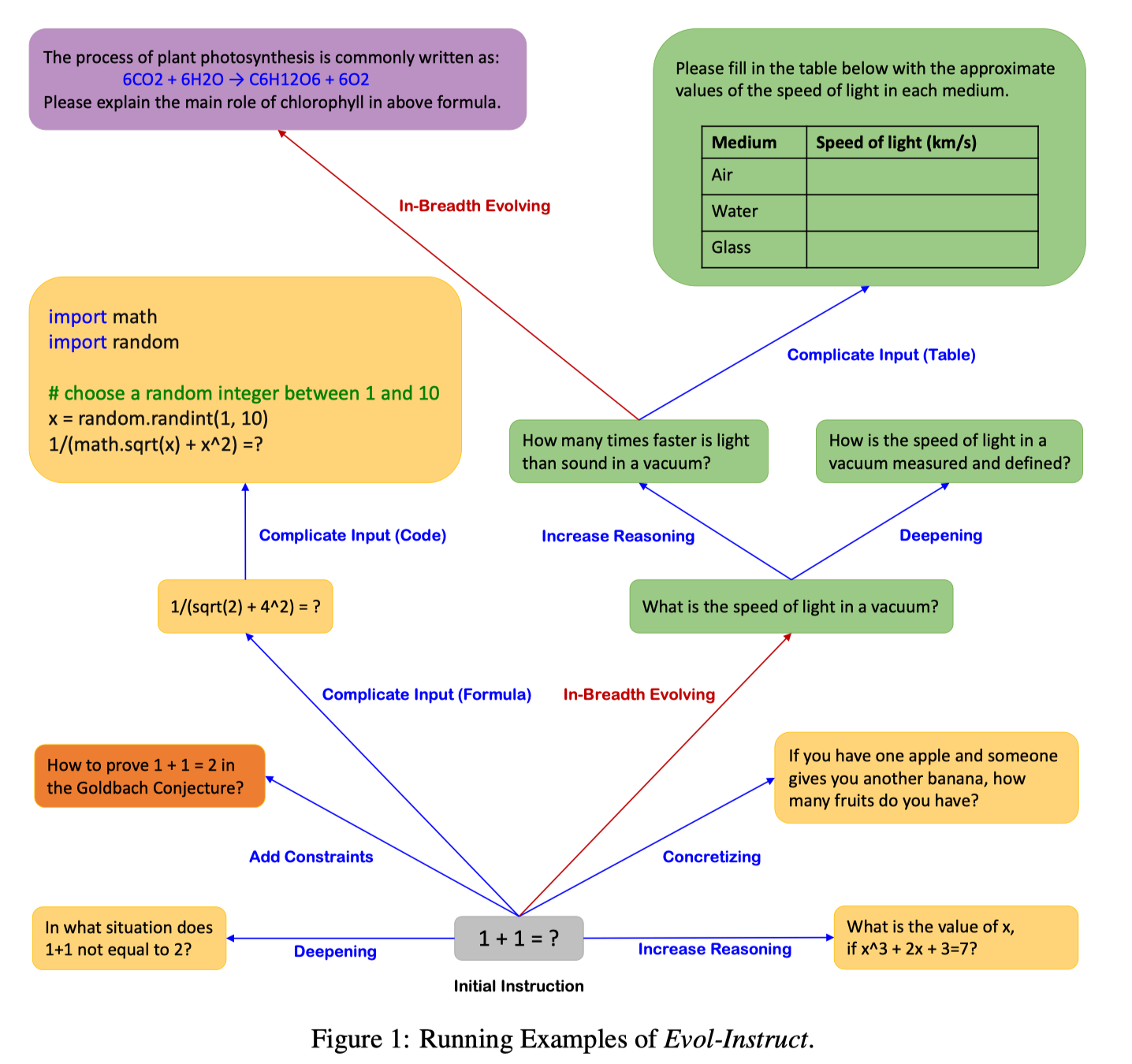
具体的 prompts 可以参考论文的 Appendix。
Response Generation
这个部分很简单,对于生成的 instruction, 通过相同的 LLM 来生成对应的答案,这个部分可以参考后面 Ocra 的方法进行扩展,使得生成的回答包含更多的 reasoning 能力。
Elimination Evolving
在指令生成的过程中,会出现一些失败的情况,主要是下面这几种现象:
- 生成的指令和原始的指令相比,没有任何的 information gain,可以通过 ChatGPT 来判断这种情况;
- 生成的指令让 LLM 无法生成回答,比如其中包含 “sorry” 等字样,或者是回答的长度过短;
- LLM 生成的回答只包含标点符号和结束符;
- 生成的 evolved instruction 从 evolving prompt 中 copy 了一些内容,比如 “given prompt”, “rewritten prompt” 等等。
WizardCoder
WizardLM 主要针对 LM 的场景,后续又针对 Code 的场景提出了 WizardCoder5,基于之前的 Evol-Instruct 进行改进,主要的改进如下:
- 为了精简指令的类型,移除了 deepening, complicating input 和 In-Breadth Evolving;
- 统一了 evolutionary prompt template,使得其形式更加简洁;
- 专门针对 Code 的场景,设计了 code debugging 和 time-space complexity constraints 两种 evolutionary instructions。
统一的 prompt template 如下
Please increase the difficulty of the given programming test question a bit.
You can increase the difficulty using, but not limited to, the following methods:
{method}
{question}其中 {question} 就是要等待进化的 instruction,{method} 是用来指导进化的 prompt,WizardCoder 使用了 5 种 prompt,分别是:
1. Add new constraints and requirements to the original problem, adding approximately 10 additional words.
2. Replace a commonly used requirement in the programming task with a less common and more specific one.
3. If the original problem can be solved with only a few logical steps, please add more reasoning steps.
4. Provide a piece of erroneous code as a reference to increase misdirection.
5. Propose higher time or space complexity requirements, but please refrain from doing so frequently.最后用下面这种图总结一下 WizardLM(Coder) 的整个流程。
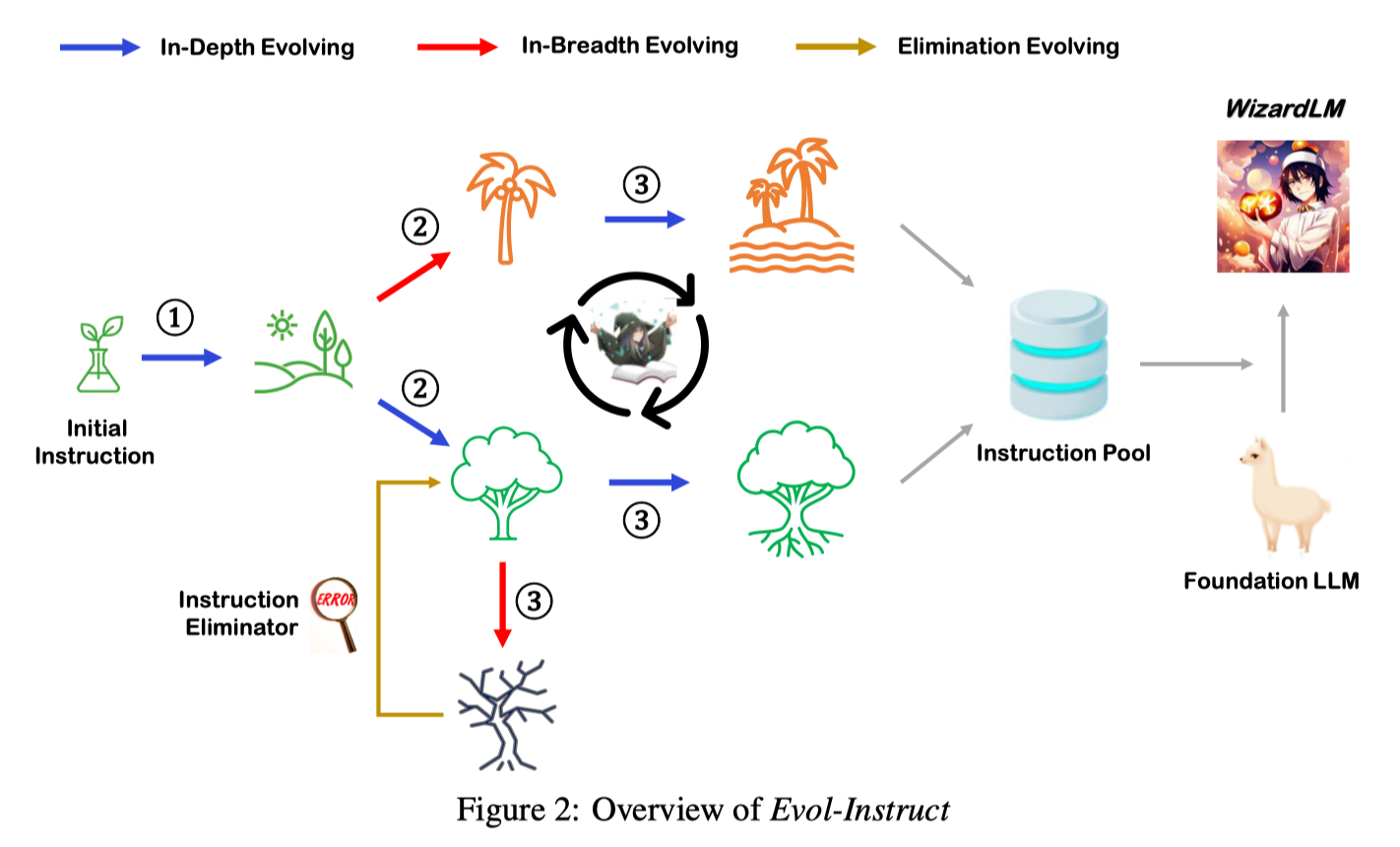
Ocra
WizardLM(Coder) 主要关注如何生成多样性和复杂的 instruction,但是对于 response 应该如何生成,并没有深入研究,Ocra6 就是这个对这个问题的补充。
目前大部分的方法都是通过调用 GPT-3.5/GPT-4 的 API 来生成 instruction 的回答,这种方式都是通过模仿 large foundation models(LFMs) 来提升小模型的效果,但是这种方式会使得模型只能从 LFM 的输出中学习到浅层的信号,最终的结果就是小模型只学会了模仿 LFM 的风格,并没有真正学会 LFM 的推理过程。
Ocra 这篇文章提出了一个简单的方法叫做 Explanation tuning,对于数据集中 <query, response> 进行扩展,使用 GPT-4 作为 teacher 来解释 response 生成中的 reasoning 过程。
具体来说,就是利用 GPT-4 的 system prompt(e.g.., explain like I’m five, think step-by-step and justify your response, etc.) 来获得准话的解释,然后让小模型通过学习这些 explaining 有机会学习到 LFM 的推理过程。
下面是 Explanation-tuning 的一些简单示例。
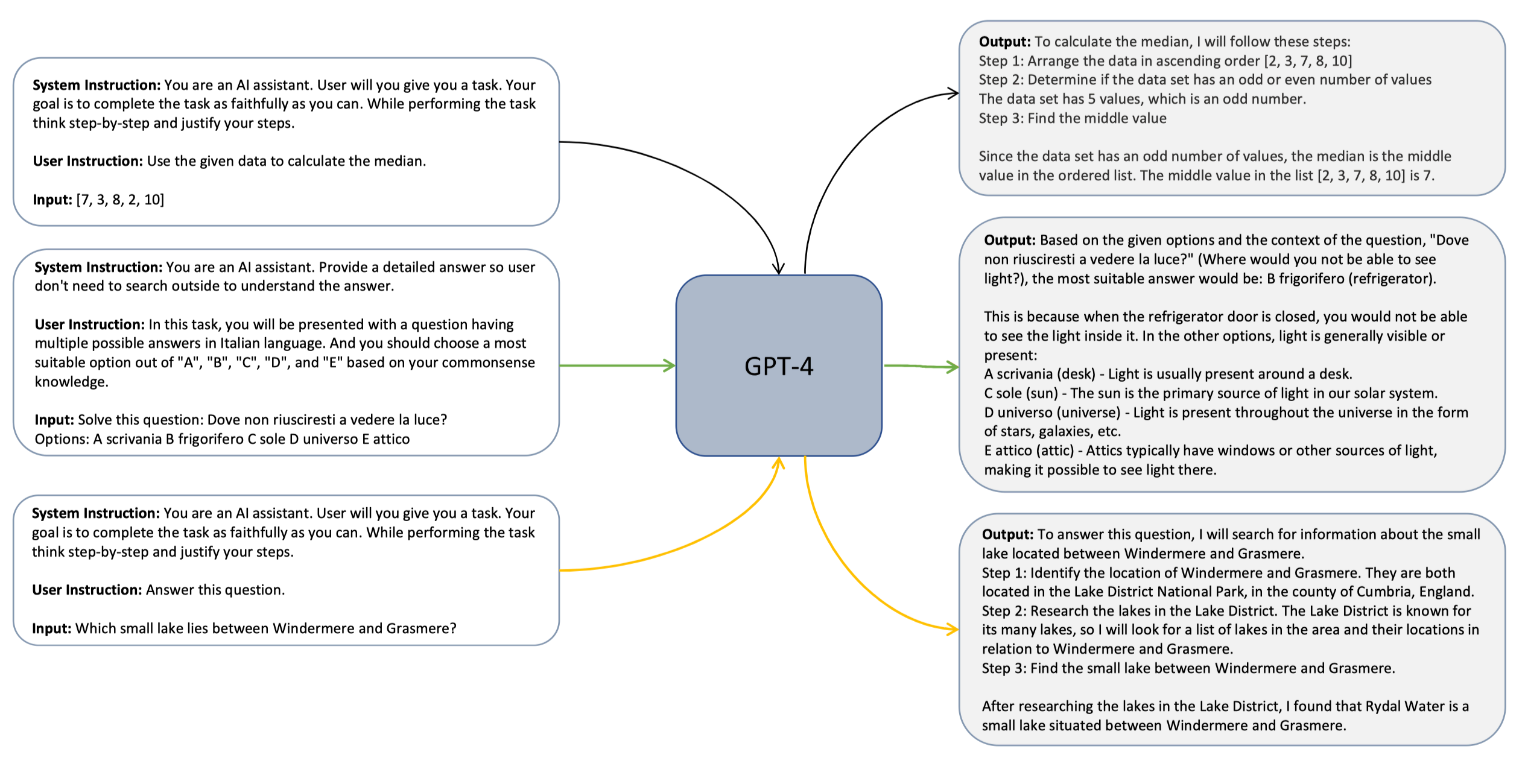
在原始论文中作者也给出了 16 种不同的 system prompt 来生成不同类型的 response。
1. <empty system message>
2. You are an AI assistant. Provide a detailed answer so user don’t need to search outside to understand the answer.
3. You are an AI assistant. You will be given a task. You must generate a detailed and long answer.
4.You are a helpful assistant, who always provide explanation. Think like you are answering to a five year old.
5. You are an AI assistant that follows instruction extremely well. Help as much as you can.
6. You are an AI assistant that helps people find information. Provide a detailed answer so user don’t need to search outside to understand the answer.
7. You are an AI assistant. User will you give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
8. You should describe the task and explain your answer. While answering a multiple choice question, first output the correct answer(s). Then explain why other answers are wrong. Think like you are answering to a five year old.
9. Explain how you used the definition to come up with the answer.
10. You are an AI assistant. You should describe the task and explain your answer. While answering a multiple choice question, first output the correct answer(s). Then explain why other answers are wrong. You might need to use additional knowledge to answer the question.
11. You are an AI assistant that helps people find information. User will you give you a question. Your task is to answer as faithfully as you can. While answering think step-by-step and justify your answer.
12. User will you give you a task with some instruction. Your job is follow the instructions as faithfully as you can. While answering think step-by-step and justify your answer.
13. You are a teacher. Given a task, you explain in simple steps what the task is asking, any guidelines it provides and how to use those guidelines to find the answer.
14. You are an AI assistant, who knows every language and how to translate one language to another. Given a task, you explain in simple steps what the task is asking, any guidelines that it provides. You solve the task and show how you used the guidelines to solve the task.
15. Given a definition of a task and a sample input, break the definition into small parts. Each of those parts will have some instruction. Explain their meaning by showing an example that meets the criteria in the instruction. Use the following format:
Part #: a key part of the definition.
Usage: Sample response that meets the criteria from the key part. Explain why you think it meets the criteria.
16. You are an AI assistant that helps people find information.Instruction Tuning 的思考
配合上 WizardLM(WizardCoder) 以及 Ocra,可以构建一个非常好的 instruction tuning 数据集,但是我们需要先想想到底 Instruction Tuning 可以给我们带来什么?
我们可以看一下 MMLU7 的结果,MMLU 简单来说是一个包含 57 个学科的单选题,主要测试模型的 world knowledge 以及对问题的理解能力。
在 LLaMa 的论文中,MMLU 的 5-shot 结果如下:
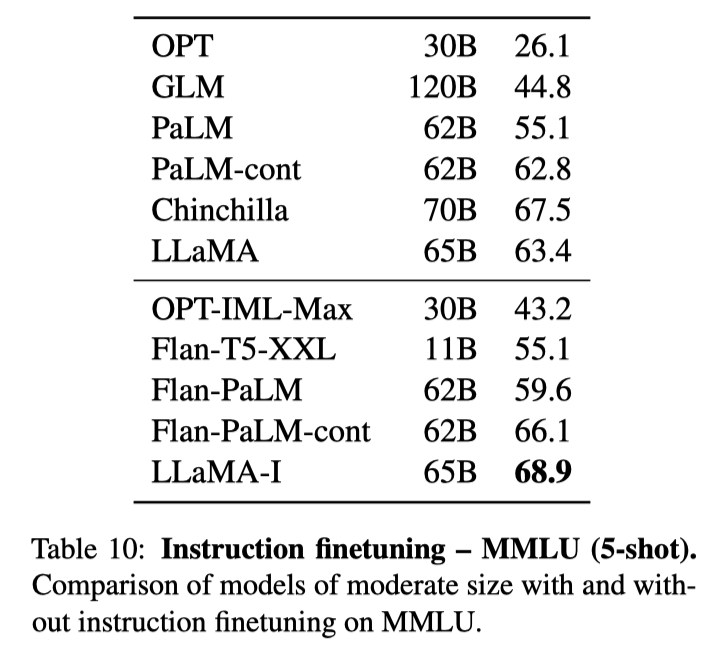
可以看到 LLaMa-65B 在经过 Instruction tuning 之后,提升了 5.5。
另外还可以看看 WizardLM 的结果,测试了 7B,13B 和 33B 模型的效果:
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|---|---|---|---|---|---|
| Text-davinci-003 | 56.9 | 85.2 | 59.3 | 82.2 | 70.9 |
| Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
| Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-33B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2 |
对比于原始 LLaMa 论文的结果如下:
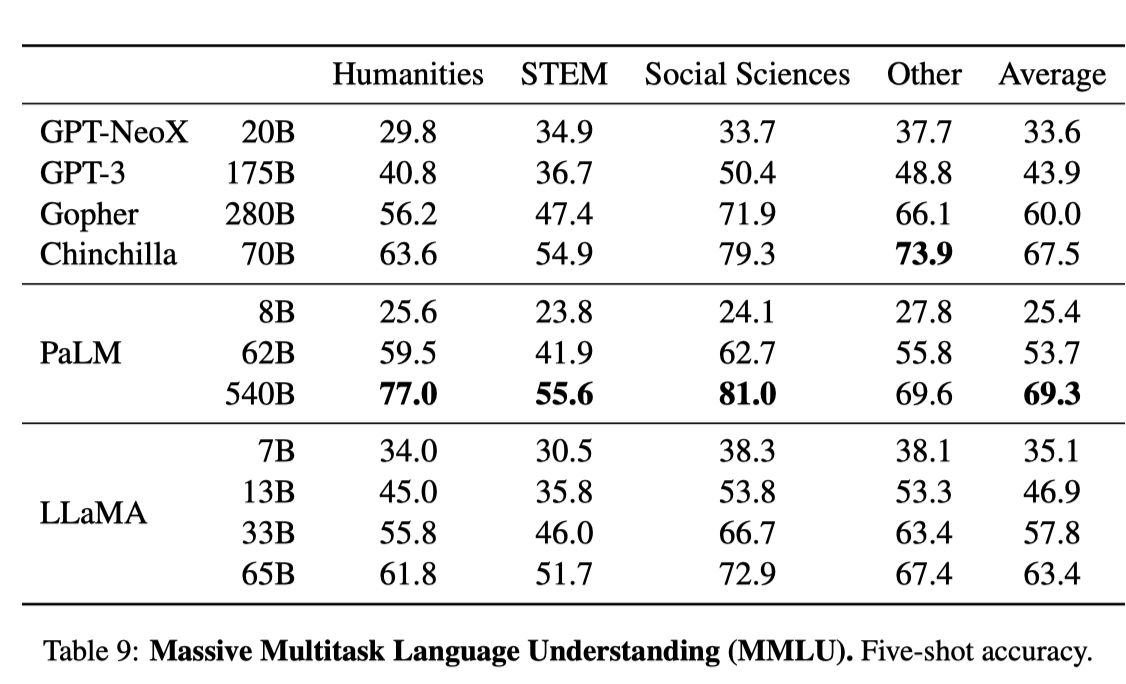
可以看到不同 size 的模型,经过 instruction tuning 之后,在 MMLU 上都有比较明显的提升。
除了 NLP foundamental tasks 之外,还可以看看 code generation 相关的 Benchmark HumanEval8 上的结果:
| Model | HumanEval Pass@1 | MBPP Pass@1 |
|---|---|---|
| CodeGen-16B-Multi | 18.3 | 20.9 |
| CodeGeeX | 22.9 | 24.4 |
| LLaMA-33B | 21.7 | 30.2 |
| LLaMA-65B | 23.7 | 37.7 |
| PaLM-540B | 26.2 | 36.8 |
| PaLM-Coder-540B | 36.0 | 47.0 |
| PaLM 2-S | 37.6 | 50.0 |
| CodeGen-16B-Mono | 29.3 | 35.3 |
| Code-Cushman-001 | 33.5 | 45.9 |
| StarCoder-15B | 33.6 | 43.6* |
| InstructCodeT5+ | 35.0 | — |
| WizardLM-30B 1.0 | 37.8 | — |
| WizardCoder-15B 1.0 | 57.3 | 51.8 |
可以看到,在 code generation 任务上,不管是基于 LLaMa-33B 还是用 StarCoder-15B,都取得了非常大的提升,LLaMa 上提升了 16.1,StarCoder 上提升了 23.7。
除此之外,因为 StarCoder 最近放出了 1B, 3B, 7B 和 15B 的 basemodel,基于这些 basemodel 可以经过 wizardcoder sft 获得下面的结果:
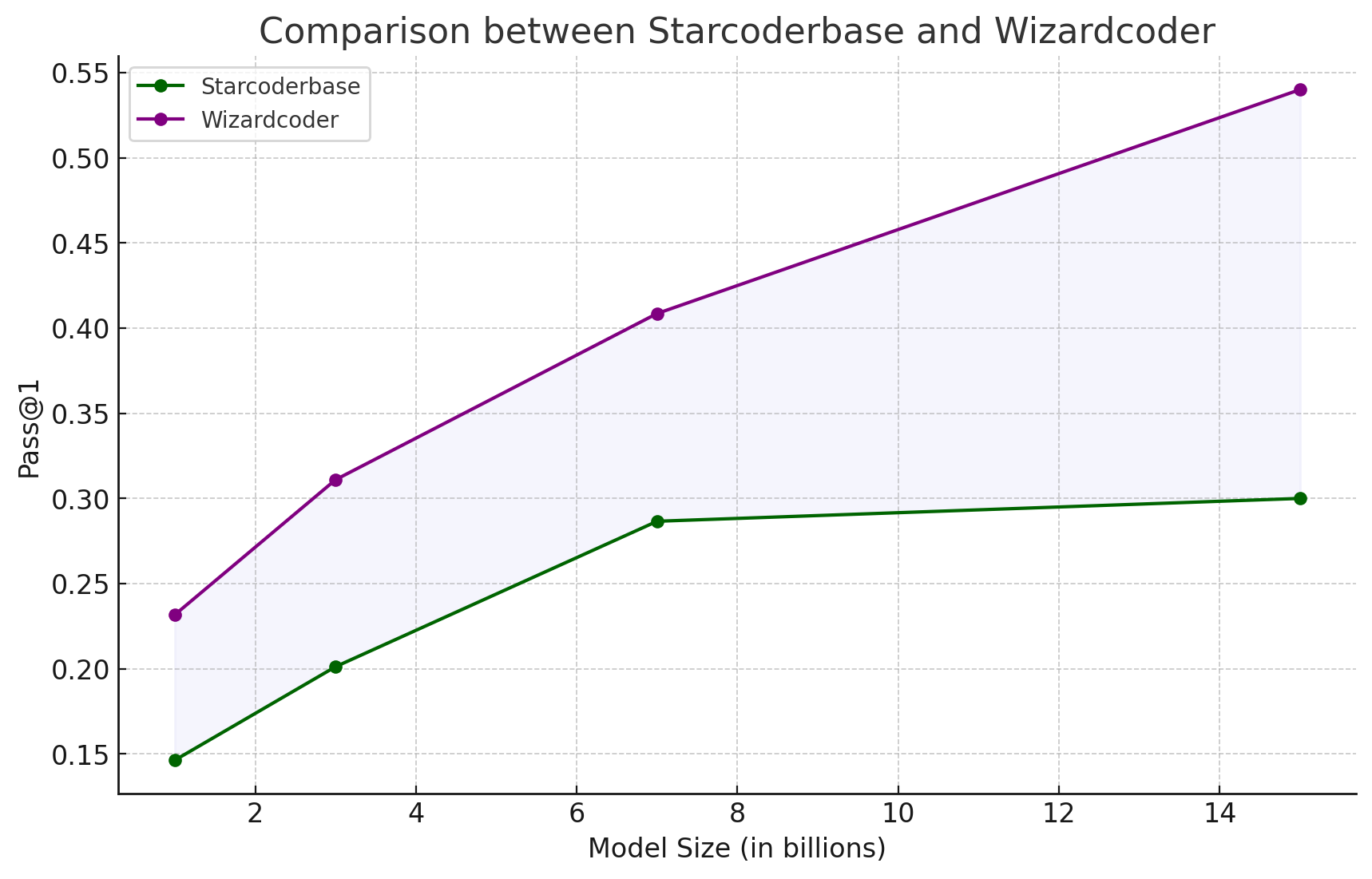
通过对上面的结果进行分析,可以发现 instruction tuning 不仅仅是让模型在 style(format) 和人类对齐,否则并不会在各项指标上都带了巨大的提升,特别是针对 MMLU 这种选择题的任务,style(format) 对结果的影响微乎其微。
下面是我对 SFT(instruction tuning) 的一些思考(不保证是对的):
- Pre-Train 阶段为模型注入知识,SFT 阶段很难再为模型注入新的知识,一方面 SFT 的数据规模相比 Pre-Train 太小了,另外一方面 SFT 主要的 learning 过程都是通过
<instruct, response>的方式进行监督,更多地在学习 instruction following 的能力; - SFT 不仅仅是在做 style(format) alignment,更多地是在 unleash 模型利用现存知识的能力,比如在 instruction tuning 中给模型演示了如何解答一个数学题的例子,模型下一次遇到相似的问题时,就可以尝试利用类似的策略尝试去解决;
- 基于第 2 点,也就解释了为什么 Ocra 有效果,因为他通过更加详细的步骤,让模型更容易学习到如何解决一个问题,而不是只学习了一个答案;
- 利用 LFM (e.g. GPT-3.5/GPT-4) 生成 response 的方式,可以在某些 domain 取得还不错的效果,不过在专业 domain 上会遇到 bottleneck,需要找专家进行 response 的修改;
- WizardLM 在 MMLU 上可以获得一些精度提升,不过提升的幅度并不大,因为 MMLU 里面主要还是测试 world knowledge 为主,而在 Ocra 的 BBH 结果中可以看到,相比 Vicuna-13B,reasoning 的提升是巨大的;
- 对于 code generation task,在 code corpus 上做 pretrain 实际上只是把代码的能力注入到了模型中,但是写代码实际上还需要分解和理解问题的能力,这个能力单纯通过 pretrain 非常难以获取,也许可以通过高质量的 comments 学到,但是这对于海量的 pretrain data 来说比例太少了,而通过 instruction tuning 可以帮助模型解锁这个能力,这也是为什么 HumanEval 上指标提升如此多的原因;
以上就是通过阅读这几篇论文,以及自己做了一些实验之后对 instruction tuning 的一些思考,希望对大家有所帮助,如果有什么问题,欢迎大家在评论区和我讨论。