As the development of Large Language Models (LLMs) progresses, the cost of inference becomes increasingly significant. Unlike training, which is typically performed once, inference is executed repeatedly. Consequently, the cost of inference begins to dominate the total cost of utilizing a model.
Given the importance of inference cost, how can we effectively benchmark it? In this post, we will explore various metrics designed specifically for benchmarking the inference process in LLMs.
Table of contents
Open Table of contents
LLM Inference
Inference is the process of using a trained model to make predictions on new data. In the context of Large Language Models (LLMs), inference refers to generating text based on a given prompt. For example, given the prompt “The quick brown fox jumps over the lazy dog,” an LLM might generate a continuation of this text.
Unlike traditional Deep Learning (DL) models, LLMs are autoregressive, meaning they generate text one token at a time. This characteristic distinguishes them from other models and influences how they are utilized.
There are typically two types of LLM serving scenarios: offline and online. In the offline scenario, inference requests are usually batched, and latency is not a significant concern. Conversely, in the online scenario, inference requests are processed as a continuous stream, making latency a critical factor to consider.
Metrics
As described above, throughout and latency are two core metrics for LLMs inference benchmarking. Let’s drill down into each of them.
Throughput
Throughput is a measure of how many units of information a system can process within a given time frame. In the context of Large Language Models (LLMs), throughput can be understood as the number of users that can be served simultaneously.
In real-world applications, each request (or prompt) often varies in context length, necessitating the simulation of these variations and the design of a suitable method to test throughput. Another critical factor to consider is the length of the generated text. In practical scenarios, this text can also vary in length, and accommodating these variations is essential for an accurate assessment of system performance.
Considering the factors of varying context lengths and generated text lengths, we can create a dummy dataset containing a list of prompts with fixed lengths and generated texts with various lengths.
Why use fixed-length prompts instead of variable-length prompts?
Fixed-length prompts make the results more consistent and easier to compare. Since throughput is primarily concerned with the model’s capacity, utilizing fixed-length prompts allows for a more accurate assessment of this capacity.
In terms of the generated text, the model often includes a special token to indicate the end of the text, making the length of the generated text unpredictable. To overcome this, we can configure the model to generate text of a specific length, ignoring the EoS(End of Sentence) token. This approach enables us to control the length of the generated text.
How should we determine the length of each generated text?
The exponential distribution can be used to simulate the length of the generated text.
Here is the figure of the exponential distribution with :
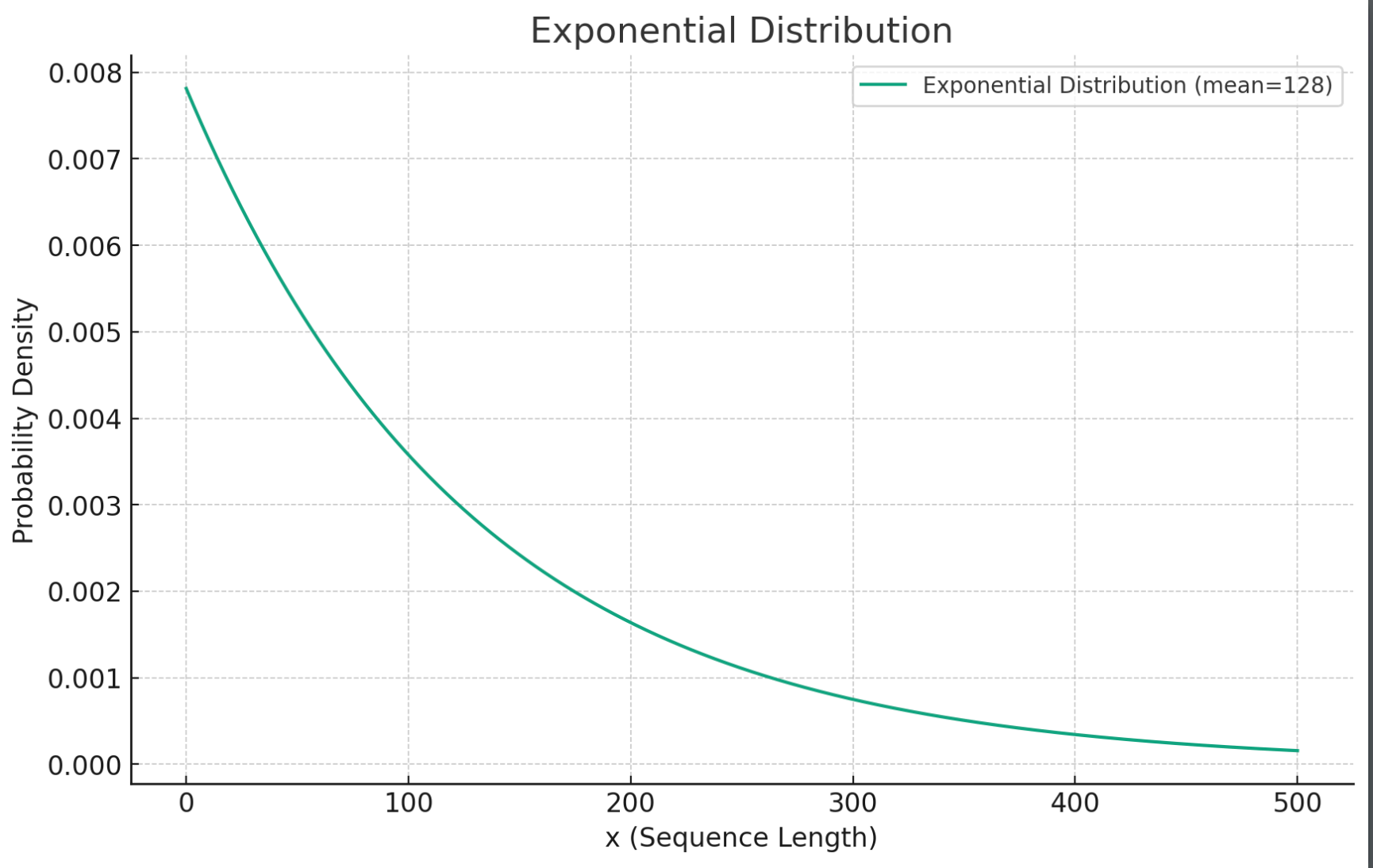
This distribution has the following characteristics:
- It’s mathematically simple, with the mean being the reciprocal of the parameter .
- Most of the samples are concentrated around the mean, and the probability of sampling a particularly large value decreases. This pattern mirrors the actual ChatGPT scenario, where most user outputs are relatively short, with only a small probability of a particularly long output.
After creating this dummy benchmark dataset, we can sample texts of different lengths to simulate various scenarios in each run which introduces variance into the benchmark, reflecting the diverse nature of real-world inputs.
Furthermore, to make model saturated, we can configure it to process as many requests as possible. This configuration aligns more closely with real-world offline scenarios.
Latency
Latency is the time it takes for a system to respond to a request. Considering each request(prompt) has a different length, we can sample a prompt length from a uniform distribution ranging from 1 to 512. This can simulate the online scenario like ChatGPT, where the user’s input is not fixed.
As for the length of the generated text, we can sample from a capped exponential distribution to ensure that the length does not exceed the model’s max_context_len.
Another character of online scenario, is that the user’s requests are not simultaneous, so we should use a strategy to model this situation.
The Poisson distribution can be used to simulate the time interval between requests. The figure of the Poisson distribution with is shown below:
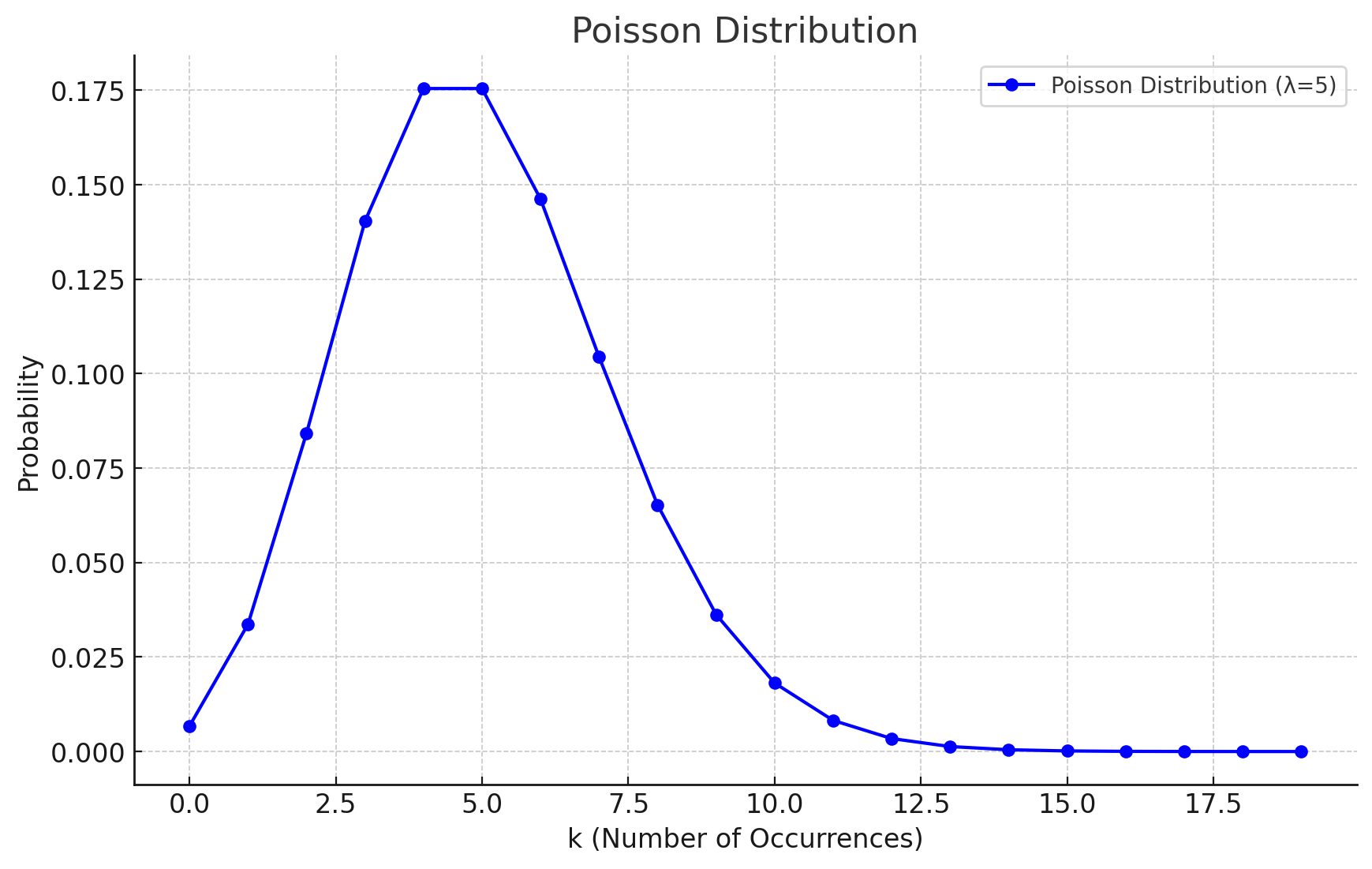
This distribution has the following characteristics:
- represents the number of events that occur in a unit of time, which can be used to represent the query-per-seconds(QPS) of the model endpoint.
- The events sampled from the Poisson distribution are guaranteed not to occur simultaneously.
Under this testing approach, we can evaluate more than just the mean latency. By sampling different percentiles of latency, such as the 90th percentile (meaning 90% of the requests are completed within this time), we gain a more nuanced understanding of the model’s performance.
After testing various inference frameworks, we can obtain example results as illustrated below:
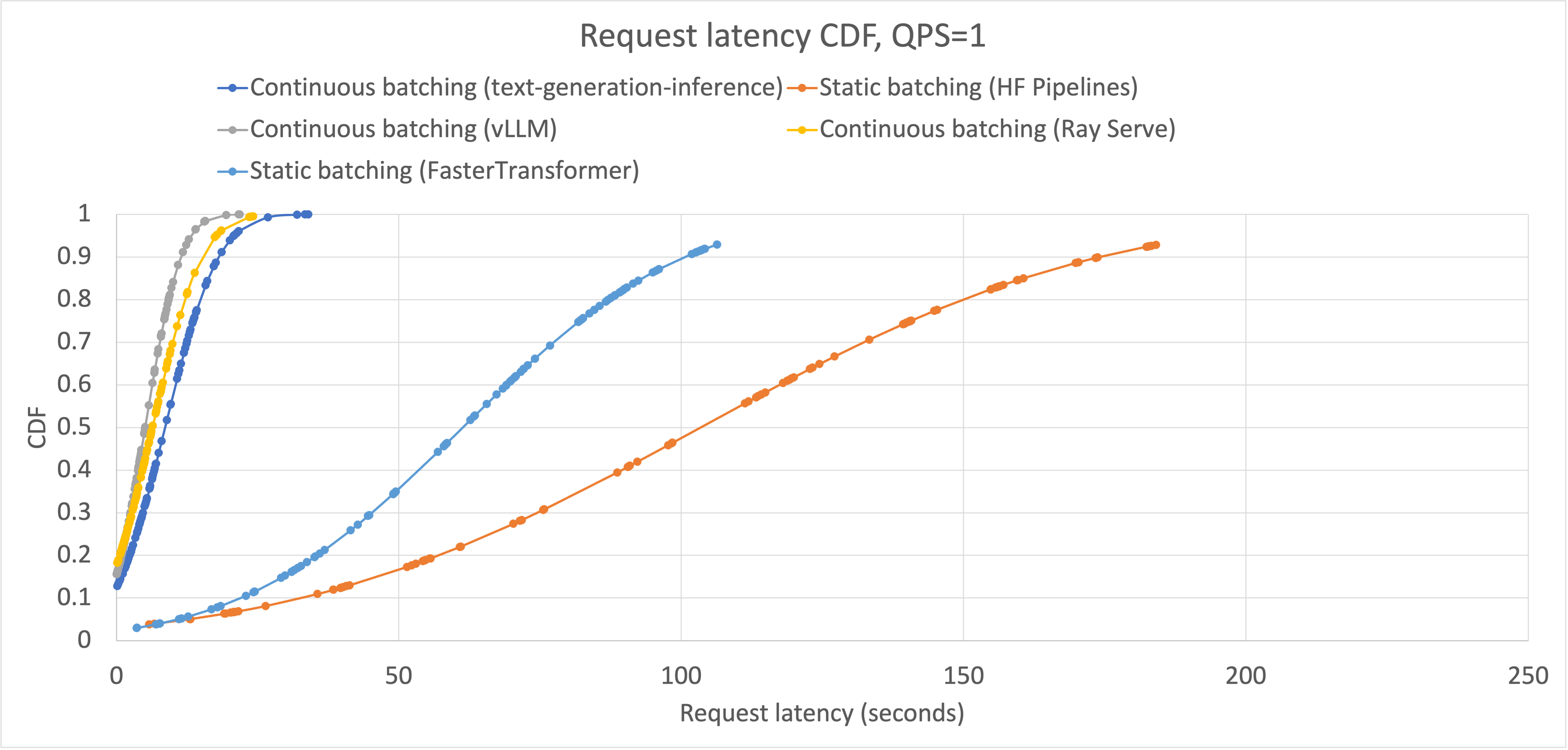
This figure allows us to examine the latency across all percentiles, providing a comprehensive view of the system’s responsiveness.
You can check out the LightLLM, TGI and vLLM benchmarks in this repo
Conclusion
In this post, we explored a range of metrics specifically tailored for benchmarking the inference process in Large Language Models (LLMs). We delved into methods for simulating different real-world scenarios and evaluating the performance of various inference frameworks.
Inference in LLMs is more complex than in standard Deep Learning (DL) models, and model inference is just one aspect of this complexity. In real-world applications, additional considerations such as scheduling, memory fragmentation, and other technical challenges must be addressed. Numerous techniques have been proposed to tackle these challenges, reflecting the multifaceted nature of LLM inference.