介绍
这篇文章是 Hinton 团队出品的,主要做的是目前炙手可热的领域,self supervised learning, 提出了一个简单的框架来解决 visual representation 中的 contrastive learning。 其实前两个月 kaiming 团队也提出了一个叫 MoCo 的方法来解决这个问题,这篇文章总体思路和 MoCo 几乎一样,最大的 contribution 我认为是去探索了框架中的每个部分分别对最终结果的影响。 最后根据论文的发现,作者调出了目前最强的结果如下,点数非常高。
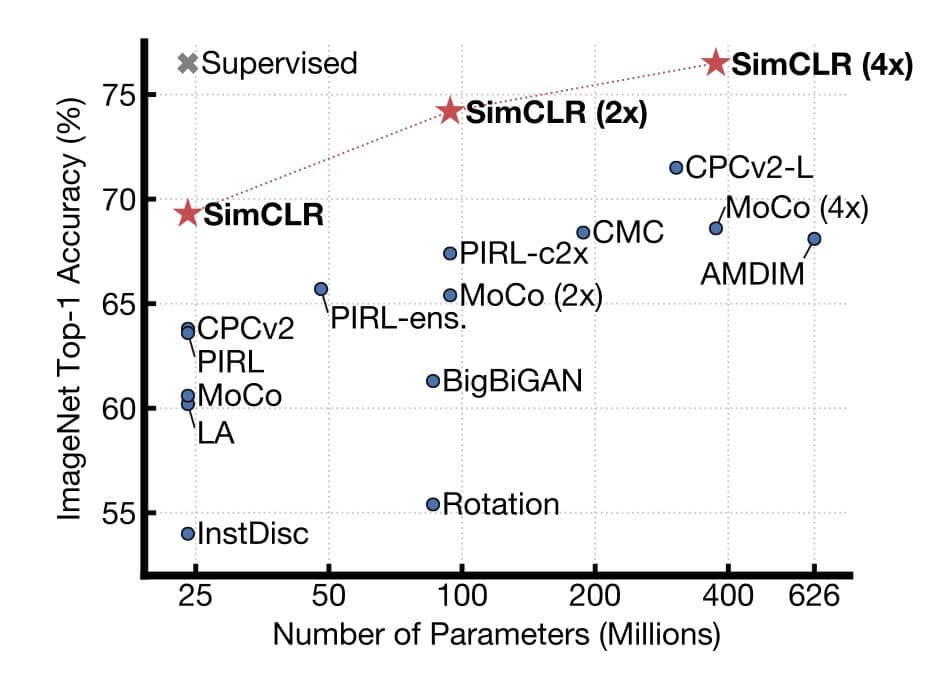
主要贡献
SimCLR 整体框架如下,和目前其他的方法是一致的
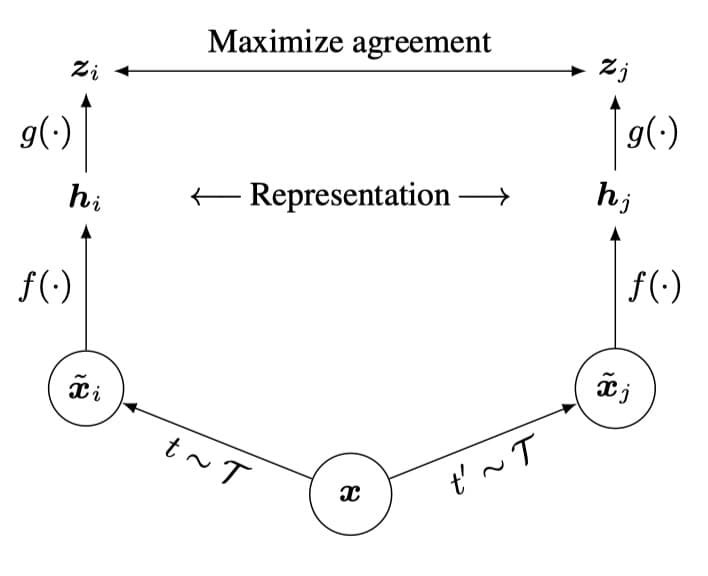
主要由四个部分组成:
- 随机数据增强
- 神经网络 encoder
- project head 进行非线性映射和降维
- contrastive loss 函数
Memory bank
这篇文章提出了可以去掉 memory bank 进行训练,实际上并不可行。 因为作者使用了 8192 的 batch size,这样每个 batch 可以产生 16382 个负样本。 当然当前 batch 提取的 feature 对比 memory bank 更好,但是这需要 128 cores 的 TPU 进行训练,对于财大气粗的 google 当然用得起,对于普通的研究人员来讲,还是老老实实用 memory bank 吧。
Global BN
使用 contrastive loss 进行训练的时候,正样本是一张相同的图片通过不同的数据增强方式得到的,这两张图片都在相同的 batch 中,这样非常因为 bn 统计量的问题出现信息泄露。 这篇文章使用了 global bn 的方式来就解决,即大 batch 下面,使用所有图片统计 bn 的均值和方差。 当然使用 MoCo 中的 suffle bn 也是可以的。
数据增强
本文系统的探索了数据增强对于表示学习的影响,其中 random cropping 和 random color distortion 是非常有用的。 random cropping 可以产生很多小 patch,但是这些小 patch 有着非常相似的颜色分布,所以可以用 color distortion 去弥补这个问题。
Projection Head
不同的 head 也有着不同的影响
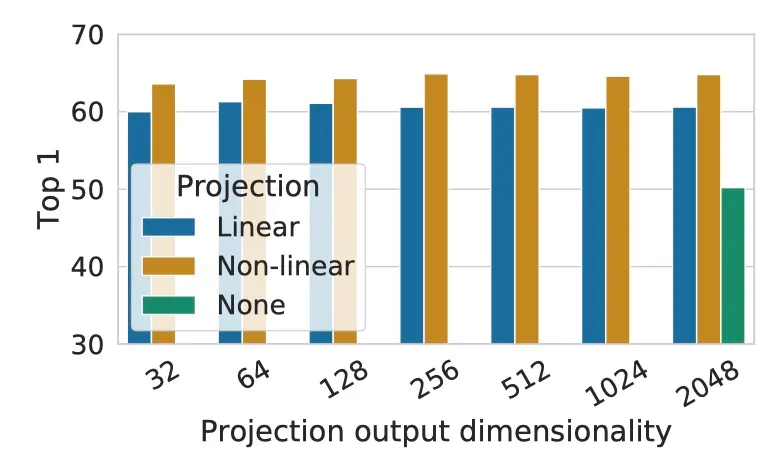
可以看出,直接使用 global average feature 效果是最差的,而一个 non-linear head 有着最好的效果。
其他的因素
除了上面这些因素之外,还用 contrastive loss 中的 temperature factor 的影响,以及是否对 feature 做归一化。 当然这些在别的 paper 中都有了结论,这里就不再赘述。
另外还有 batch size 的影响,因为其没有用 memory bank,当然 batch size 越大,包含越多的负样本,效果越好。
总结
总体来说,这篇文章通过了很多实验来验证到底是哪些因素影响了 SSL 的效果。 很多结论也非常 solid,效果也非常好,可以指导很多调参的工作, 但是 novelty 上并没有给人太大的启发。