Problems
随着 LLM 不断 scale,模型的 size 越来越大,量化也变成了一个必要的部分。之前在 llm-quantization-review 已经介绍过 llm 量化面临的基本问题以及当时的解决方案。
随着社区对 llm 量化的不断研究,发现 llm activation 呈现出了更复杂的 pattern,由之前观察到的结构化 outlier 变成了没有规律的 massive activations。具体来说,outlier 的表现是 activation 在一些固定维度展现出比较大的值,与整个序列中 token 位置没有关系,而 massive token 是指 activation 会在前几个 token 的某些维度出现异常大的值,后续不再出现。
current methods
由于 activation 范式的改变,之前比较有效的 smoothquant 变得比较乏力,在整个社区的推动下,llm 量化开始向旋转优化上靠拢,最开始研究将旋转矩阵引入量化的工作是 QuIP# 和 QuaRot。这两篇文章指出可以对所有 linear 的输入增加一个旋转变换,同时对 weight 做一个逆变换来保证等价性,由于旋转矩阵天然具有均匀化的作用,同时旋转特性可以将旋转矩阵穿透 rmsnorm 实现和上一层的 linear 权重进行融合,从而类似 smoothquant 的融合效果,也就是推理时并不会增加任何的 overhead。
笔者不在这篇 blog 中过多介绍旋转量化的基础内容,感兴趣的读者可以自行阅读上面两篇论文掌握相关的 context。这篇 blog 更关心旋转矩阵的后续问题,也就是如何选择旋转矩阵,即如何优化旋转矩阵。
在 QuaRot 论文中,通过实验发现随机 Hadamard 矩阵比随机正交矩阵有更好的效果,而 SpinQuant 则做了
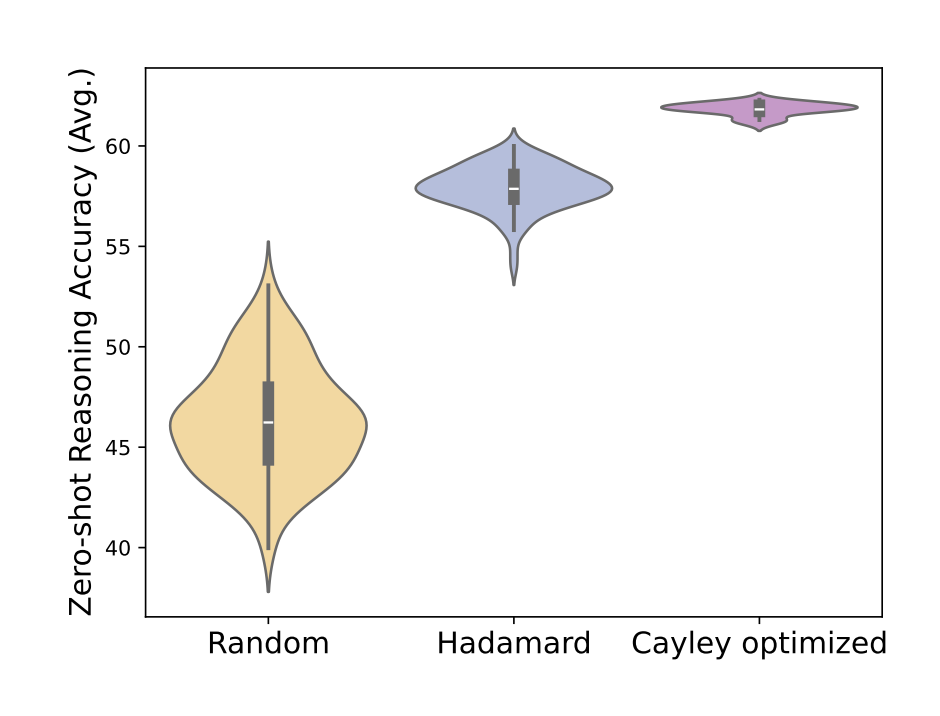
在 DFRot 这篇论文中,作者通过对比随机 Hadamard 变换和随机正交变换在量化中的表现,发现对于普通 token,两者在消除 outlier 方面的效果差不多,但是对于 massive activations,Hadamard 矩阵可以轻微降低这些 token 的量化误差,而随机旋转矩阵反而会增加这个 token 的量化误差。