Intro
在 GPT-OSS 发布之前,我就知道了 NVFP4 这种数据类型,是在读 SVDQuant 论文的时候了解的。这次 GPT-OSS 发布直接端出来一个新的 4‑bit 数据类型——MXFP4,我觉得有必要搞懂这两个数据类型的计算流程以及主要区别,可以在后续搞 4bit 量化的时候更有针对性。
下面分别介绍一下 MXFP4 和 NVFP4 这两种数据类型的具体定义以及计算方式,梳理一下两者之间的异同。
MXFP4
要介绍 MXFP4,就需要了解 MX‑compliant format,其中就会有 MXFP4 的例子。
在 2023 年 9 月,几家芯片大厂(NVIDIA、AMD、Intel 等)联合发布了一个 MX‑format 的技术报告,这个技术报告中定义了 MX‑compliant format,其包含下面三个组成部分:
- Scale(X) data type;
- Private elements ($P_i$) data type;
- Scaling block size (k).
下面一张图可以简单的描述这三个组成部分。
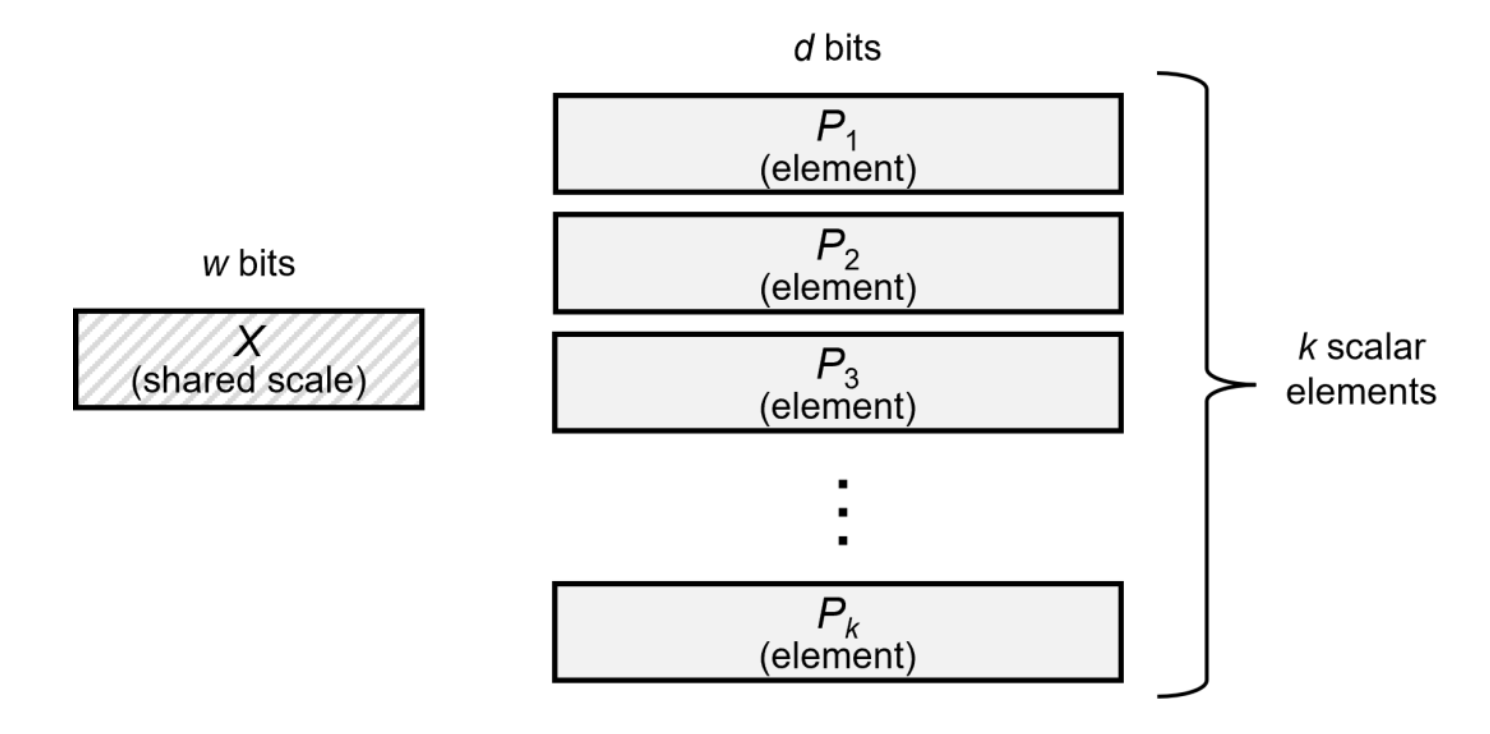
其中 $P_1, P_2, \dots P_k$ 就是一个 block 中的所有 elements,每个 element 都是 d bits,其共享同一个 scaling factor X。
下面是几种 MX‑compliant format 的例子,从这些例子中可以看到 MX format 最大的特点就是它的 scale dtype 是 FP8(E8M0),而不是之前普通格式里面的 scale dtype 是 FP32 或 BF16.
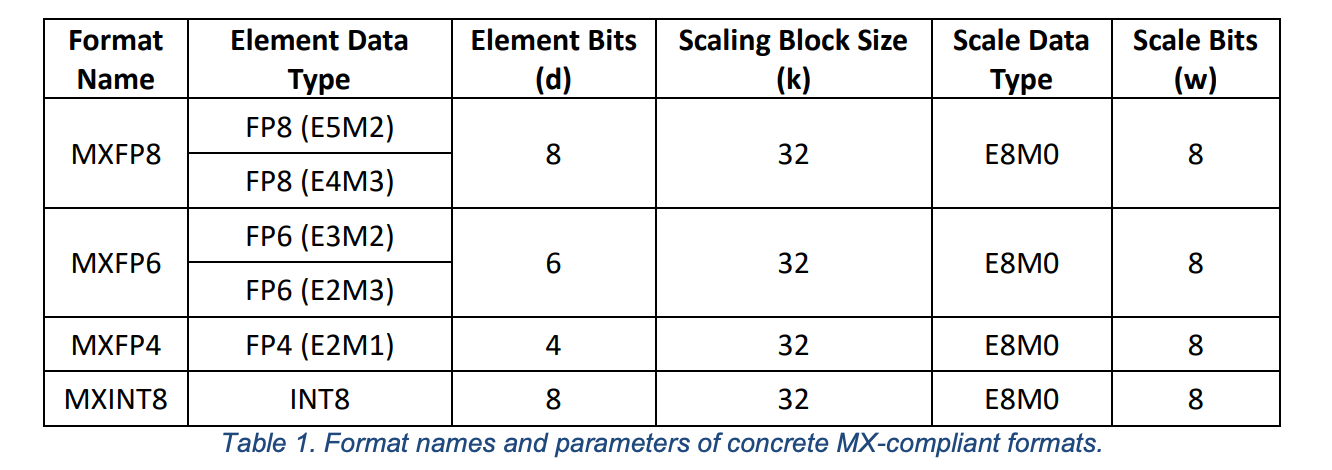
采用 FP8(E8M0)作为 scale dtype 不仅可以节约显存,还可以提高计算速度。比如一个 4‑bit 编码,block_size=32,那么 32 个 FP 数仅仅只需要 17 bytes 就可以进行压缩,其中 8(scale) + 32×4($P_i$) = 136 bits = 17 bytes。
而对于计算来说,两个 MX‑compliant format 可以通过下面的方式计算点积
$$C = \text{Dot}(A, B) = X^{(A)} X^{(B)} \sum_{i=1}^{k} \left( P_i^{(A)} \times P_i^{(B)} \right)$$又由于 MX 使用 power‑of‑two 的 scale(E8M0),这使得重标定(rescale)非常容易,可以通过移位(shift)操作来实现,这样对于编译器/硬件更友好。
这种方案虽然速度上很快,但是有一个明显的缺点,就是 scale dtype 采用了 FP8(E8M0),虽然它的数值范围大,但是存在精度不足的缺点,最终会影响量化的精度。
NVFP4
上面提到的 MXFP4 格式由于采用了 FP8(E8M0)作为 scale dtype,所以在精度上存在明显的缺陷,而精度是量化里非常重要的一个考虑因素。因此,NVIDIA 在一篇博客里提出了一种新的 4‑bit 格式——NVFP4。
首先我们用里面的一张图来简单描述一下具体的计算流程
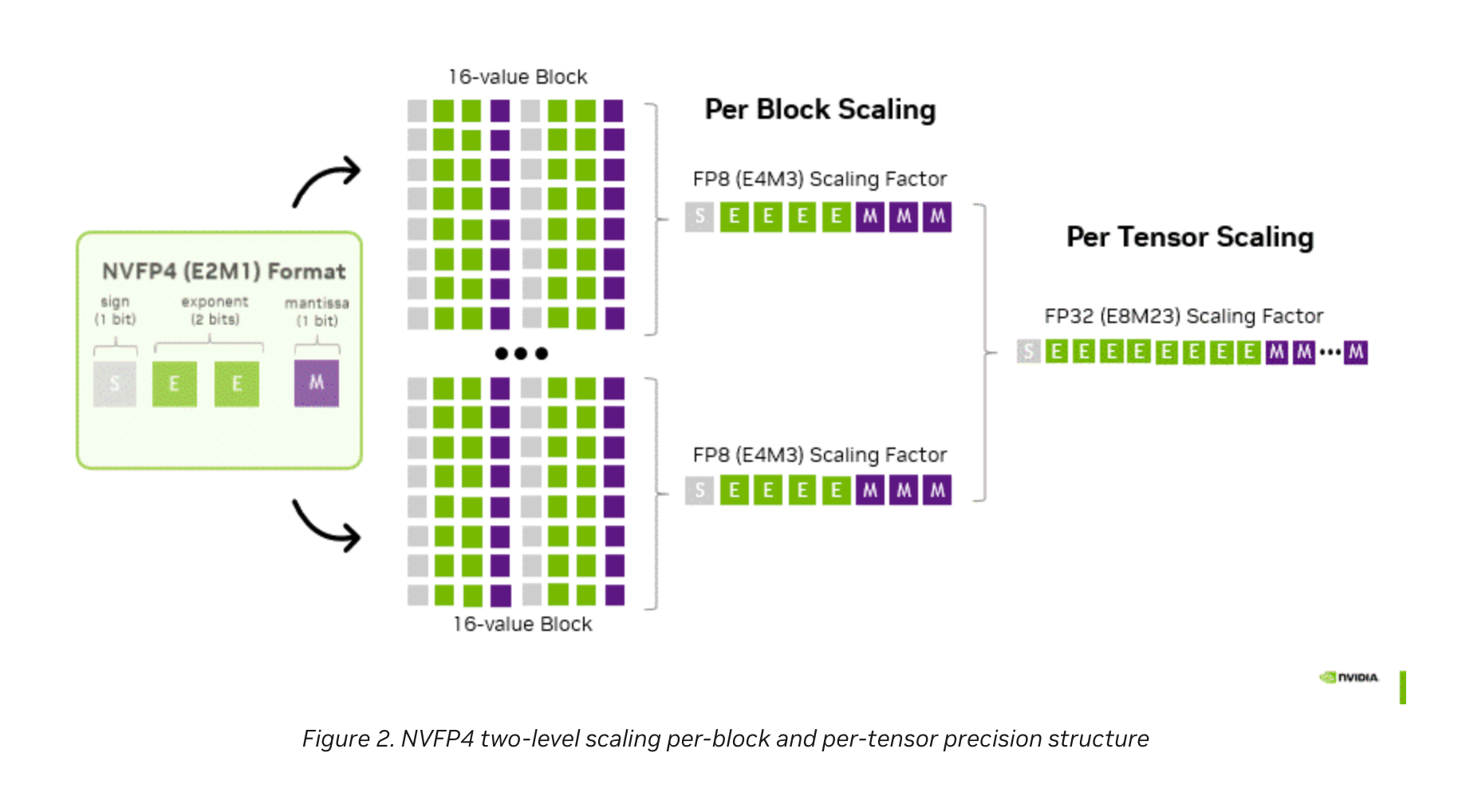
从图上可以看出,NVFP4(E2M1)的 4 个 bit 位的分布情况,其中一个符号位,2 个指数位,最后有一个小数位。和之前常见的 fp8(e4m3),MXFP4 等格式不同的是,它采用了一个两阶段的 scaling,其中第一个 level 是 per-block/group scaling,block 大小是 16,scaling factor 是 FP8(E4M3)的数据类型;第二阶段采用的是 per-tensor scaling,其中 scaling factor 是 FP32 的数据类型。
比如之前 DeepSeek 采用的 block‑wise FP8(E4M3)量化方案,使用的是 128×128 block,每个 block 采用单阶段 scaling,其中 scaling factor 是 FP32 数据类型。
NVFP4 如此设计自然是为了解决 MXFP4 存在的问题。首先第一个问题就是要解决 scale dtype 是 FP8(E8M0)这个精度不足的问题。
对于 scale dtype 的选择来说,采用 FP32 当然是精度最高的做法,但是这样会有额外的显存开销,且计算效率也不够高。所以 NVFP4 依然采用 FP8 的 scale dtype,但是考虑到 E8M0 在精度上存在的问题,NVFP4 则选择了 E4M3 的格式。
但是考虑到 E4M3 能够表示的数值范围是有限的,只能从 -448 到 +448,这会导致 scale data 落在 E4M3 的盲区,所以引入了二阶段的 per‑tensor FP32 scale 进行补偿,以覆盖更大的范围。
最终的计算方式就是 x ≈ q4(E2M1) * s_block(E4M3) * s_tensor(FP32),比较简单,相比之前的计算方式,只是在最终的结果上增加了一个标量 scale。
Conclusion
最后总结一下 MXFP4 和 NVFP4 的区别如下。
| dtype | group size | scale dtype | additional scale |
|---|---|---|---|
| MXFP4 | 32 | FP8(E8M0) | No |
| NVFP4 | 16 | FP8(E4M3) | FP32 per‑tensor scale |
在具体计算时,MXFP4 和 NVFP4 目前仅在最新的 NVIDIA B 系列显卡上原生支持。推理时可将 activation 动态量化为 NVFP4,然后执行 NVFP4 GEMM 实现加速,最终再将结果 dequant 回 BF16。相较于 NVFP4,MXFP4 的 scale 仅涉及指数移位,且没有额外的 per‑tensor FP32 scale,理论上会更快一些。对于非 B 系列显卡,只能将 NVFP4/MXFP4 dequant 回 BF16 再执行 BF16 GEMM,这种方式仅在 memory‑bound 场景下有加速效果,更适合端侧、低并发请求的场景。