LLM inference challenges
目前 LLM 推理有一个大的问题还是 kv cache 上,特别是现在 long context 已经成了 LLM 的标配,而且大家的使用场景也会用更多的 context,这时 kv cache 占据的 GPU Memory 开始显著地增加,导致 LLM 推理不仅推理变慢,而且能同时推理的 batch 也变小了。
之前比较流行的解决方案是 GQA(Grouped-Query Attention) 和 MQA(Multi-Query Attention),下面是一个简单的图示,展示了标准的 MHA(Multi-Head Attnetion) 和 MQA 以及 GQA 的对比。
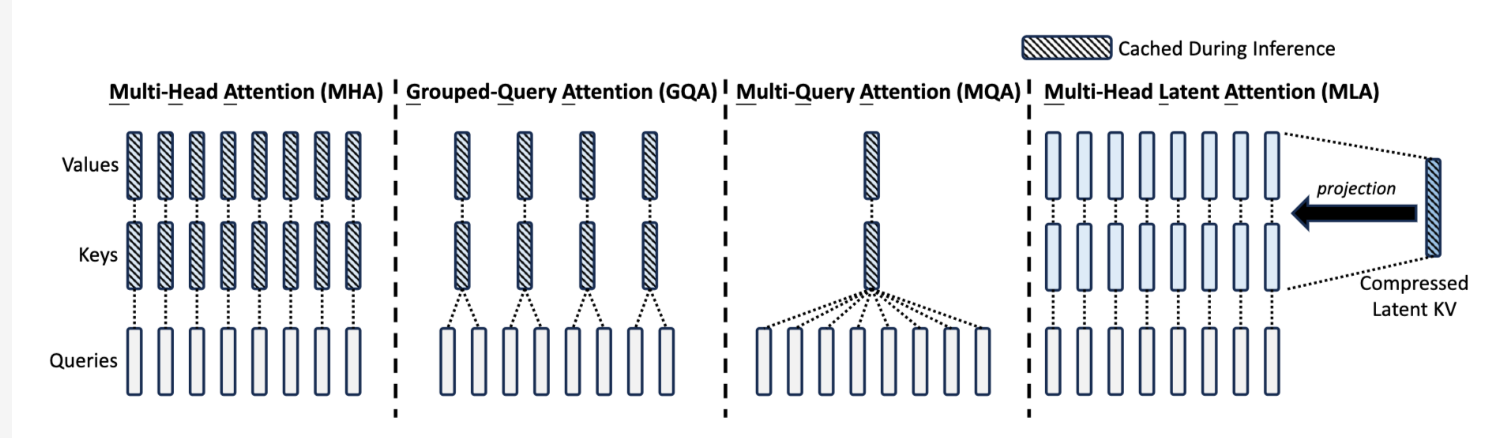
GQA 和 MQA 都是通过减少 kv head 的数量来减少 kv cache 的存储,但是天下没有免费的午餐,减少了 head number 必定会带了一些负面影响,下面是 deepseek-v2 论文中对 GQA 以及 MQA 做的实验结果。
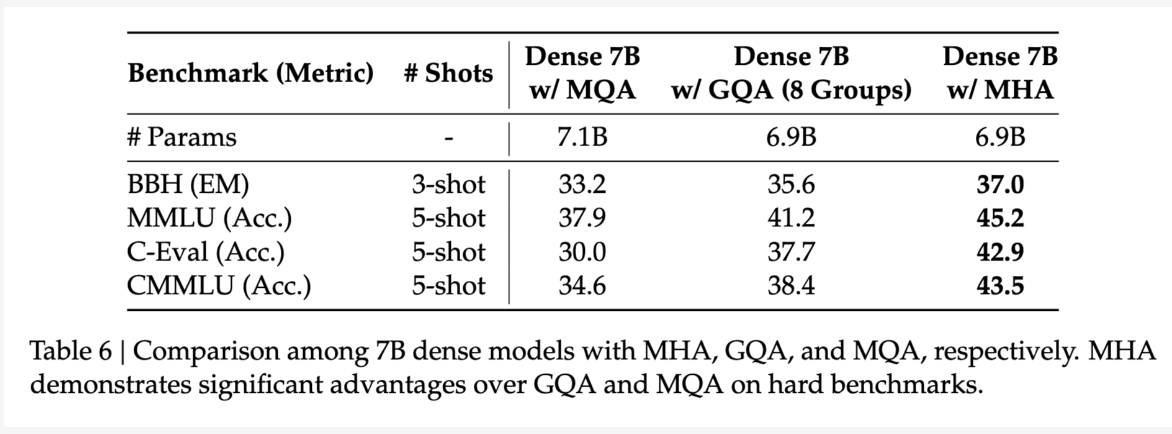
可以看到,采用了 GQA 和 MQA 之后,相比 MHA 都出现了比较明显的掉点,哪怕 GQA 通过对 head 分组来延缓掉点的情况,但是精度的损失依然比较显著。
Solutions in DeepSeek-v2
在 DeepSeek-v2 中提出了 MLA(Multi-Head Latent Attention) 来解决这个问题,下面具体来介绍一下这个方案是如何实现的,以及他在推理效率上的提升和精度上的结果。
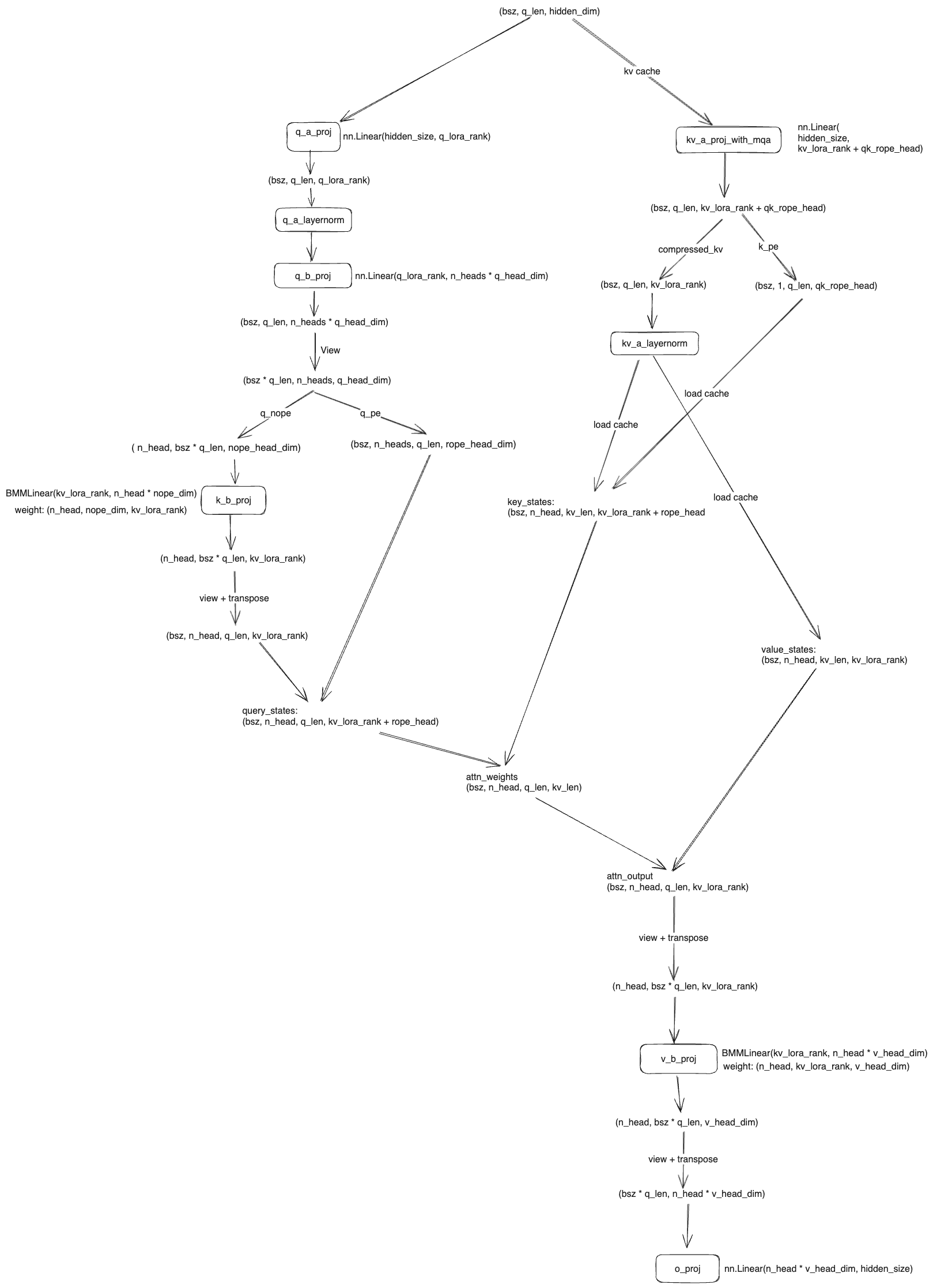
Low-Rank Key-Value Joint Compression
MLA 主要是通过对 kv 实现一个 low-rank 的联合压缩,假如 $h_t$ 表示 attention 的输入,那么正常的 Multi-Head Attention 首先会通过下面的公式计算 $q_k$, $k_t$ 和 $v_t$
$$q_t = W^Q h_t \\ k_t = W^K h_t \\ v_t = W^V h_t$$接着再通过 softmax 计算 attention
$$o_t = \text{Softmax}(\frac{q^T k}{\sqrt{d_h}}) v$$MLA 是希望对 K 和 V 进行压缩,提出了下面的公式
$$ \begin{align} c_t^{KV} = W^{DKV}h_t \\ k_t^C = W^{UK}c_t^{KV} \\ v_t^C = W^{UV} c_t^{KV} \end{align} $$对于输入 $h_t$ 首先通过 $W^{DKV}$ 对其进行降维压缩,其中 $c_t^{KV} \in R^{d_c}$ ,然后 $d_c \ll d_hn_h$ 就可以实现压缩的目的。但是压缩之后的 latent vector 不能直接使用,需要恢复到原始的维度,可以通过 $W^{UK} c_t^{KV}$ 对 k 进行 up-projection,v 也是同理的。这样 cache 就不需要保存原始的 $k_t$ 和 $v_t$ 只需要保存压缩之后的 $c_t^{KV}$ 即可,达到了缩小 kv cache 的目的。
另外注意到 $h_t \in R^{d_h n_h}$ 和 $W^{DKV} \in R^{d_c \times d_hn_h}$,也就是说 $c_t^{KV}$ 直接压缩了所有的 head 而不是单个 head。然后 $W^{UK} \in R^{d_hn_h \times d_c}$,也就是说对压缩进行恢复的时候,也是恢复的所有的 head。 除此之外,还有一个好处就是在推理的过程中可以把权重 $W^{UK}$ 吸收进 $W^Q$, $W^{UV}$ 吸收进 $W^O$,从而实现更快地推理。
权重融合的推导
下面可以推导一下 $W^{UK}$ 吸收进 $W^Q$ 的过程。
对于 $q_t^T k_t$ 的过程,这里表示单个 head,可以将 up-projection 带进去
$$ \begin{align} q_t^T k_t &= h_t^T (W_i^Q)^T W_i^{UK} C_T^{KV} \\ &= h_t^T (\tilde{W_i^Q})^T C_T^{KV} \\ &= \tilde{q_t}^T C_T^{KV} \end{align} $$这里 $\tilde{W_i^Q}$ 就是 merge 之后单个 query head 的权重,可以 concat 所有 head 的权重获得最终的 $\tilde{W^Q}$,在和输入 $h_t$ 计算得到 $\tilde{q}_t$ 之后,就可以 load $C_T^{KV}$ 进行常规的 attention 计算。
下面推导一下 $W^{UV}$ 吸收进 $W^O$ 的过程,还是对于单个 head 进行分析。
$$ \begin{align} u_{t,i} &= W^O_i \sum_{j=1}^t\text{Softmax}(\frac{q_{t,i}^T k_{j,i}}{\sqrt{d_h}}) v_{j,i} \\ &= W^O_i [\alpha_1, \alpha_2, \cdots \alpha_n] V_{j,i} \end{align} $$仍然可以把 up-projection 带进去,可以得到下面的结果
$$ \begin{align} u_{t,i} &= W^O_i [\alpha_1, \alpha_2, \cdots \alpha_n] W_i^{UV}C_t^{KV} \\ &=[\alpha_1, \alpha_2, \cdots \alpha_n] W^O_i W_i^{UV}C_t^{KV} \\ &=[\alpha_1, \alpha_2, \cdots \alpha_n] \tilde{W}^O_i C_t^{KV} \\ &= \tilde{W}^O_i [\alpha_1, \alpha_2, \cdots \alpha_n] C_t^{KV} \end{align} $$通过上面的公式可以看到 $W^Q$ 吸收了 $W^{UK}$, $W^O$ 吸收了 $W^{UV}$,这样的好处就是不需要升维 $c_t^{KV}$ 到实际的 KV,可以像正常的 attention 那样进行计算。
这样做的好处当然显而易见,可以节约 kv cache 存储的大小,在 long context 下可以更高效地推理,那么有没有什么坏处呢?
维度推导
我们可以推导一下 $\tilde{W}^Q$ 的维度信息,可以从单个 head 开始推导。
$$(\tilde{W_i}^Q)^T = (W_i^Q)^T W_i^{UK}$$其中 $W_i^Q \in R^{d_h \times h}$, $W_i^{UK} \in R^{d_h \times d_c}$,那么 $\tilde{W_i}^Q \in R^{d_c \times h}$,所以吸收权重之后的 $\tilde{W_i}^Q$ 相比原始的 $W_i^Q$ 增加的倍数是 $\frac{d_c}{d_h}$,根据论文中的数值 $d_c=512, d_h=128$ 所以是会增加 4 倍的大小和计算量。
接着推导 $\tilde{W}^O$ 的维度信息,也从单个 head 进行推导。
$$\tilde{W_i}^O=W_i^O W_i^{UV}$$其中 $W_i^O \in R^{d_h \times h}$, $W_i^{UV} \in R^{d_n \times d_c}$,那么 $\tilde{W_i}^O \in R^{d_c \times h}$,所以吸收权重之后的 $\tilde{W_i}^O$ 也增加了 4 倍的大小和计算量。
TODO(xingyu): 补充一下正确的优化方案