LayerNorm 是 LLM 里面很常见的操作,就像 BatchNorm 在 CV 里面的地位,他的作用可以让模型训练稳定,加速收敛等。他的前向过程比较简单,但是反向计算梯度的流程比较复杂,算是神经网络里面求梯度最复杂的几个算子之一了,这篇文章记录 LayerNorm 前向和反向的流程,以及 torch 的简单实现。
Forward Pass
前向过程的计算流程比较直接,沿着特征维度计算均值 $\mu$ 和对应的方差,然后对 $x_i$ 做标准化获得 $\hat{x}_i$,最后再执行 element-wise affine 获得最终的结果,整体计算比较直观,具体的公式如下
$$ \begin{align*} \mu &= \frac{1}{m} \sum_{i=1}^m x_i \\ \sigma^2 &= \frac{1}{m} \sum_{i=1}^m (x_i - \mu)^2 \\ \hat{x}_i &= \frac{x_i - \mu}{\sqrt{\sigma^2 + \varepsilon}} \\ y_i &= \gamma \hat{x}_i + \beta \end{align*} $$Backward Pass
反向过程梯度的计算非常复杂,其中 $\beta$ 和 $\gamma$ 的梯度计算比较简单,但是反向传播的过程,需要计算 $x_i$ 的梯度,这个过程非常复杂。
首先可以把简单的梯度公式写下来,即 $\beta$,$\gamma$ 的梯度计算,公式如下。
$$ \begin{align*} \frac{\partial L}{\partial \beta} &= \sum_{i=1}^n \frac{\partial L}{\partial y_i} \\ \frac{\partial L}{\partial \gamma} &= \sum_{i=1}^n \frac{\partial L}{\partial y_i} \hat{x}_i \\ \end{align*} $$为了简化,将 x 的 batch 维度和 sequence 维度合并在一起,有 $\mathbf{x} \in \mathbb{R}^{n \times m}$,由于 $\gamma$ 和 $\beta$ 是分别作用在每个 token 上的,所以他们的梯度需要在 token 维度进行求和。 另外也可以从维度的角度来解释,$\frac{\partial L}{\partial y_i} \in \mathbb{R}^{n \times m}$,而 $\gamma \in \mathbb{R}^{m}$,我们知道一个 tensor 的梯度和它本身的 shape 应该一样,所以需要在 n 维度进行求和。
接下来需要进行 dx 的梯度计算,这是最复杂的,再开始推导之前,我们先画一下计算图。
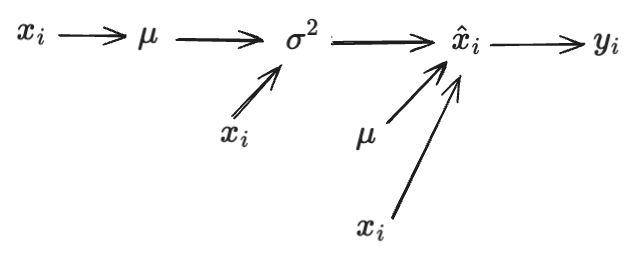
从计算图中可以看出,$x_i$ 有三条路径对 $y_i$ 有贡献,那么 dx 就是三条路径梯度的求和,而三条路径在 $y_i$ 之前交汇于 $\hat{x}_i$,所以可以先求 $d \hat{x}$,公式如下
$$ \frac{\partial L}{\partial \hat{x}_i} = \frac{\partial L}{\partial y_i} \gamma $$下面开始推导 dx 的公式,先把三条路的链式法则写出来。
$$ \frac{\partial L}{\partial x_i} = \frac{\partial L}{\partial \hat{x}_i} \frac{\partial \hat{x}_i}{\partial x_i} + \frac{\partial L}{\partial \sigma^2} \frac{\partial \sigma^2}{\partial x_i} + \frac{\partial L}{\partial \mu} \frac{\partial \mu}{\partial x_i} $$下面分别来求每条路径的 dx。
上面的第一项比较简单,直接列出。
$$ \frac{\partial L}{\partial \hat{x}_i} \frac{\partial \hat{x}_i}{\partial x_i} = \frac{1}{\sqrt{\sigma^2 + \varepsilon}} \frac{\partial L}{\partial \hat{x}_i} $$第二项需要分别求 $\frac{\partial L}{\partial \sigma^2}$ 和 $\frac{\partial \sigma^2}{\partial x_i}$,我们分别进行推导。
对于第一项,有下面的推导
$$ \begin{align*} \frac{\partial L}{\partial \sigma^2} &= \sum_{i=1}^m \frac{\partial L}{\partial \hat{x}_i} \frac{\partial \hat{x}_i}{\partial \sigma^2} \\ &= \sum_{i=1}^m \frac{\partial L}{\partial \hat{x}_i} \left[ -\frac{1}{2} \frac{x_i - \mu}{\sigma^2 + \epsilon} \frac{1}{\sqrt{\sigma^2 + \epsilon}} \right] \end{align*} $$对于第二项,有下面的推导
$$ \frac{\partial \sigma^2}{\partial x_i} = \frac{2}{m} (x_i - \mu) $$所以
$$ \frac{\partial L}{\partial \sigma^2} \frac{\partial \sigma^2}{\partial x_i} = -\frac{1}{m} \frac{1}{\sqrt{\sigma^2 + \epsilon}} \frac{x_i - \mu}{\sigma^2 + \epsilon} \sum_{i=1}^m \frac{\partial L}{\partial \hat{x}_i} (x_i - \mu) $$最后来推导第三项 $\frac{\partial L}{\partial \mu}$ 和 $\frac{\partial \mu}{\partial x_i}$。
首先来推导 $\frac{\partial L}{\partial \mu}$,从计算图中可以观察到,$\mu$ 也是由两条路径决定的,所以需要对两条路径的梯度进行求和。
$$ \frac{\partial L}{\partial \mu} = \sum_{i=1}^m \frac{\partial L}{\partial \hat{x}_i} \frac{\partial \hat{x}_i}{\partial \mu} + \frac{\partial L}{\partial \sigma^2} \frac{\partial \sigma^2}{\partial \mu} $$注意到下面的推导公式
$$ \frac{\partial \sigma^2}{\partial \mu} = -\frac{2}{m} \sum_{i=1}^m (x_i - \mu) = 0 $$所以上面对于 $\frac{\partial L}{\partial \mu}$ 里面的第二项为 0,可以不用计算,只需要计算第一项。
$$ \frac{\partial \hat{x}_i}{\partial \mu} = - \frac{1}{\sqrt{\sigma^2 + \epsilon}} $$接着推导剩下的最后一项就非常简单了。
$$ \frac{\partial \mu}{\partial x_i} = \frac{1}{m} $$上面已经把所有公式都计算好了,最后把他们组合在一起,可以得到
$$ \begin{align*} \frac{\partial L}{\partial x_i} &= \frac{\partial L}{\partial \hat{x}_i} \frac{\partial \hat{x}_i}{\partial x_i} + \frac{\partial L}{\partial \sigma^2} \frac{\partial \sigma^2}{\partial x_i} + \frac{\partial L}{\partial \mu} \frac{\partial \mu}{\partial x_i} \\[2ex] &= \frac{1}{\sqrt{\sigma^2 + \varepsilon}} \left[\frac{\partial L}{\partial \hat{x}_i} - \frac{1}{m}\sum_{j=1}^m\frac{\partial L}{\partial \hat{x}_j} - \frac{(x_i - \mu)}{\sqrt{\sigma^2 + \varepsilon}} \cdot \frac{1}{m}\sum_{j=1}^m\frac{\partial L}{\partial \hat{x}_j}\frac{(x_j - \mu)}{\sqrt{\sigma^2 + \varepsilon}}\right] \end{align*} $$Torch Implementation
下面通过 torch 来实现一下前向和反向的逻辑。
Forward Impl.
前向的逻辑很简单,照着上面的公式依次实现即可,注意 LayerNorm 是沿着特征维度计算 $\mu$ 和 $\sigma^2$,最后将 x, w, mean, rstd 都 cache 起来,方便反向计算的时候进行使用。
class LayerNorm:
@staticmethod
def forward(x, w, b):
# x is the input activations, of shape B,T,C
# w are the weights, of shape C
# b are the biases, of shape C
B, T, C = x.size()
# calculate the mean
mean = x.sum(-1, keepdim=True) / C # B,T,1
# calculate the variance
xshift = x - mean # B,T,C
var = (xshift**2).sum(-1, keepdim=True) / C # B,T,1
# calculate the inverse standard deviation: **0.5 is sqrt, **-0.5 is 1/sqrt
rstd = (var + eps) ** -0.5 # B,T,1
# normalize the input activations
norm = xshift * rstd # B,T,C
# scale and shift the normalized activations at the end
out = norm * w + b # B,T,C
# return the output and the cache, of variables needed later during the backward pass
cache = (x, w, mean, rstd)
return out, cache
Backward Impl.
反向的逻辑比较复杂,根据上面推导的公式,可以先计算 $\frac{\partial L}{\partial \hat{x}_i}$,它是每一项的基础,在代码中,我们用 dnorm 来表示。
接着计算括号里面的每一项,第一项就是 dnorm,第二项就是 dnorm.mean(dim=-1),第三项就是 norm * (dnorm * norm).mean(dim=-1),括号外最后再乘上 rstd 即可。
class LayerNorm:
@staticmethod
def backward(dout, cache):
x, w, mean, rstd = cache
# recompute the norm (save memory at the cost of compute)
norm = (x - mean) * rstd
B, T, C = x.size()
dw = (dout * norm).sum(dim=(0, 1))
db = dout.sum(dim=(0, 1))
dnorm = dout * w
dx = (
dnorm
- dnorm.mean(dim=-1, keepdim=True)
- norm * (dnorm * norm).mean(dim=-1, keepdim=True)
)
dx *= rstd
return dw, db, dx
可以通过 torch 自带的 autograd 去验证我们计算的梯度结果。
B = 2 # some toy numbers here
T = 3
C = 4
x = torch.randn(B, T, C, requires_grad=True)
w = torch.randn(C, requires_grad=True)
b = torch.randn(C, requires_grad=True)
out, cache = LayerNorm.forward(x, w, b) # B,T,C
dout = torch.randn(B, T, C)
fakeloss = (out * dout).sum()
fakeloss.backward()
dw, db, dx = LayerNorm.backward(dout, cache)
print("dx error:", (x.grad - dx).abs().max().item())
print("dw error:", (w.grad - dw).abs().max().item())
print("db error:", (b.grad - db).abs().max().item())
获得的输出如下,可以看到我们计算的梯度和 torch 算出来的梯度非常接近,说明我们的推导是正确的。
dx error: 8.344650268554688e-07
dw error: 0.0
db error: 0.0
Reference
https://github.com/karpathy/llm.c/blob/master/doc/layernorm/layernorm.md