0x0 问题的开始
一般在 NVIDIA 的显卡上部署模型都会使用 TensorRT,同时 TensorRT 也提供了很多默认的优化,比如 kernel fusion、graph optimization 以及 FP16 推理等等。一般这些优化都会默认打开,大部分情况模型的推理结果都不会有太大的区别,不过最近笔者却发现打开 FP16 推理却会出现较大的 diff。
模型是一个 CNN + Transformer 的结构,使用 FP32 推理的时候 diff 非常小,而且之前也测试过 FP16 推理,虽然和 PyTorch 的推理结果相比有一定的误差,比如有一些 box regression 的误差有 0.3 左右,不过这个也在我们可以接受的范围内。
但是最近用了更多的数据集训练模型之后,模型突然出现 FP16 结果和 PyTorch diff 相差特别大的情况,有的误差达到了 3-5,这明显是不正常的,需要好好查找出现的问题。
0x1 FP32 和 FP16 的代沟
首先我们排除模型本身在转换过程中的问题,因为 TensorRT FP32 的推理结果和 PyTorch 的推理结果是很接近的,所以问题就锁定在 FP16 推理上。
0x1.1 TensorRT FP16 Inference
首先回顾一下 TensorRT FP16 推理的流程,在推理过程中,网络的权重和输入都会 cast 成 FP16,所有中间的 activation 也会使用 FP16 来进行存储和处理,这样在计算和访问的时候,相比 FP32 可以带来明显的性能提升。
下面是 FP32 和 FP16 所表示的范围,一般来说,inputs 和 weights 在 cast 成 FP16 的时候都不会有什么问题,特别是模型在训练收敛之后,dynamic range 一般都在 FP16 之内,就算在范围外,在 cast 成 FP16 也不会有太大的误差,我们可以通过遍历模型的权重来 check 参数的范围是否在 FP16 的范围呢。
import torch
state_dict = torch.load("model_final.pth")["model"]
for name, param in state_dict.items():
max_val = torch.abs(param.data).max()
if max_val > 2**15:
abs_diff = torch.abs(param.data.to(torch.float16) - param.data).max()
print(f"Parameter '{name}' and fp16 range diff: {abs_diff}.")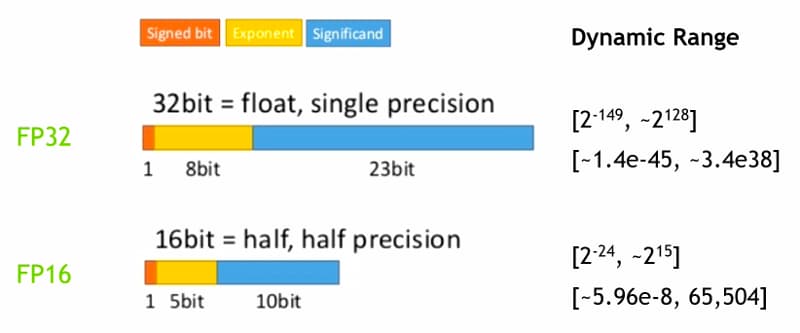
而输入一般会做 normalization,所以也不会超过 FP16 的 dynamic range,唯一有可能出问题就是中间的 activation 的计算,可能存在溢出的问题。
0x1.2 AMP Training Recap
一般来说,为了让模型在使用 FP16 进行推理的时候,也能输出正常的结果,我们会采样混合精度训练的方式,在训练过程中使用 FP16 进行 Forward/Backward pass,下面我们简单回顾一下 AMP Training 的原理。
在 MIXED PRECISION TRAINING 这篇论文中,作者提出了混合精度训练的原理,我们也可以用一张图来简单表示整体的训练流程。
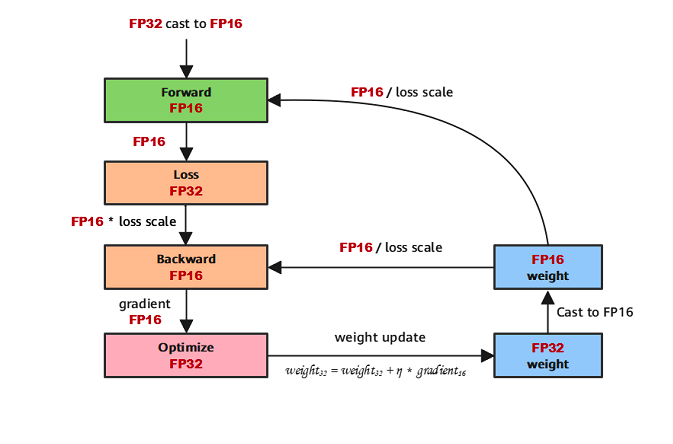
其中要特别注意以下 3 点,weight backup,loss scaling 以及 FP16 white list。
0x1.1.1 weight backup
在混合精度训练的时候,需要使用 FP16 进行 forward&backward pass 来达到加速的目的,但是在 backward 的过程中,gradient 很容易出现数值不稳定的问题,所以保留 weight 的 FP32 精度可以更好的防止这个问题。
0x1.1.2 loss scaling
因为 backward 的时候梯度非常小,在 FP16 容易出现 underflow 的问题导致 gradient 为 0,这样参数就没有办法更新了。所以采用 loss scaling 的方式,在 loss 做 backward 之前乘上一个比较大的系数,将 gradient 拉到 FP16 可以表示的范围内,在更新的时候采用精度更高的 FP32。
0x1.1.2 FP16 white list
有一些操作在 FP16 下是数值不稳定的,比如 normalization 操作,因为他们要算输入的统计量,这些统计量在 FP16 会被截断,这样会造成训练过程中数值稳定性的问题,可能会使得训练不收敛。一些常见的 FP32 white list 就是各种 normalize 操作,softmax,一些需要使用 log 的激活函数或者是矩阵求逆的运算等等。
0x2 寻找错误的原因
模型在训练的时候使用了混合精度,整个 forward 过程其实已经在用 FP16 做计算了,正常来说模型在推理阶段直接使用 FP16 进行推理是不应该出现问题的,实际上可以用 PyTorch 模型进行 FP16 的推理做验证,只需要在模型推理的时候加上下面的代码,可以验证在 PyTorch 下 FP16 和 FP32 的误差很小。
with torch.no_grad() and torch.autocast("cuda", enabled=fp16_mode):
outputs = model.forward(inputs)所以问题就出在 TensorRT 的模型导出上, 因为 TensorRT 会在内部做一些优化,比如 layer fusion 等,所以大概率是模型在 fusion 之后,某些 layer 的 FP16 精度出现上溢或者下溢的问题,导致最终模型的输出结果异常。
0x2.0 二分法定位
因为 TensorRT 是一个黑盒,没有开源 inference 的代码,而 onnx 模型通过 TensorRT parser 之后,得到的模型结构和 layer 名称完全对不上,所以没有办法显式地和 PyTorch 中的每一层对齐,可以通过遍历只能通过。